デイリーAIダイジェスト — 2026-05-12
arXiv ハイライト
Soohak: 数学者が監修した、LLMの研究レベル数学能力を評価するベンチマーク
問題と動機
フロンティアLLMがIMOの金メダル相当の性能に達して以来、オリンピック形式のベンチマークは上位層における識別力を失っています。研究レベルの数学が次の自然な目標となります。これはステップバイステップの推論を必要とする点では同様ですが、開かれた数学的知識により近い問題に適用されます。既存の研究レベルベンチマークは規模が小さく——Riemann-Benchは25問、FrontierMath-Tier 4は50問——フロンティアシステム間の統計的な識別が信頼できません。Soohak(SH^2、수학 시험「数学試験」に由来)は、64名の数学者によって一から作成された439問のベンチマークと、より大きなMiniスプリットから構成され、規模と難易度の両立を目的として設計されています。
構築
貢献者の全プールは、31の組織にわたる105名の採択問題作成者に達しています:48%が教員、23%が大学院生・ポスドク、25%が学部生、5%が非公開です。86名の一次システム貢献者のうち72名は、数学科への直接アプローチを通じて採用されました。報酬は採択問題数に基づき、総額$260{,}000のプールから1問あたり$36から$3{,}623(貢献者あたり上限$20{,}000)が支払われました。すべての提出物は英語または韓国語によるテキストのみのLaTeXであり、完全な解答と明示的な最終解答行を含んでいます。貢献者はAI使用を禁じたオリジナリティ条項、NDA、およびIP譲渡契約に署名しました。
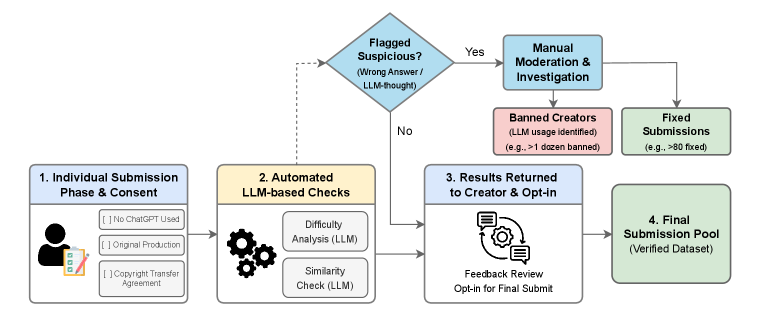
パイプラインは多段階のフィルタから構成されています:オリジナリティ・著作権の合意、モデルゲートを用いたルーティングと類似性チェックによる自動スクリーニング、2名の人間レビュアー、貢献者によるオプトイン、最終採択という流れです。AI生成と判断された提出物があった場合、その貢献者はすべてのデータから除外されます(「禁止クリエイター」)。モデルゲートによるルーティングは運用上重要です:複数のフロンティアモデルが容易に解ける問題はMiniにルーティングされ、モデルゲートを通過した問題はChallengeに収録されます。
ベンチマークは以下のスプリットに分かれます: - SOOHAK-Mini(n=702):最初の2つの内部モデルゲートをマージしたもの;オリンピックレベルから初期大学院レベルまで。 - SOOHAK Challenge(n=340):難易度が高く、研究色の強い問題。 - SOOHAK Refusal(n=99):不適切に設定された問題の認識を試る独立したスプリット——これは研究数学に固有の能力であり、新しい問題に取り組む際の最初の課題は、しばしばその問題が適切に設定されているかを判断することです。
評価プロトコル
11のモデルがreasoningを有効にした状態で評価されました:Gemini-3-Pro/Flash、GPT-5/-Mini(Medium reasoning)、Claude-Opus-4.5/Sonnet-4.5、Grok-4.1-Fast(クローズド);Qwen3-235B-A22B-thinking-2507、GPT-OSS-120B、Kimi-2.5、GLM-5(オープンウェイト)。報告されるメトリクスはAvg@3とPass@3であり、最終解答の正誤のみに基づくスコアリングで、部分点はありません。
主な結果
Miniにおいて、フロンティアモデルは僅差で集まっています:GPT-5がAvg@3で72.22、Gemini-3-Proが71.70、Grok-4.1-Fastが70.66をリードしています。難易度による分離はChallengeで現れます:
| モデル | Challenge Avg@3 | Pass@3 |
|---|---|---|
| Gemini-3-Pro | 30.39 | 44.12 |
| GPT-5 | 26.37 | 40.88 |
| Grok-4.1-Fast | 18.43 | 30.88 |
| GPT-5-Mini | 18.82 | 28.82 |
| Gemini-3-Flash | 15.69 | 25.59 |
| Kimi-2.5 | 13.87 | 20.00 |
| GPT-OSS-120B | 11.27 | 18.53 |
| Claude-Opus-4.5 | 10.39 | 18.82 |
| GLM-5 | 9.61 | 18.24 |
| Qwen3-235B | 8.04 | 15.00 |
| Claude-Sonnet-4.5 | 5.69 | 10.29 |
すべてのオープンウェイトモデルはAvg@3で15%を下回っています。Challengeの問題のうち124問はいずれの評価モデルによっても解かれておらず、170問はそのファミリー全体で未解決または不正解となっており——これはRiemann-Benchの未解決数(\geq 23/25)の全体をすでに上回っています。
Refusalでは異なる順位付けが得られます。GLM-5がAvg@3/Pass@3で49.49/73.74をリードし、GPT-OSS-120Bが43.77/60.61、GPT-5が43.09/61.62と続きます。Qwen3-235BはAvg@3で2.69と崩壊しており——ほとんど不適切設定の問題を識別できておらず、適切設定の確認を上書きする解答出力バイアスが示唆されます。ChallengeランクとRefusalランクの分離は、解くことと解不能性の認識が現在のpost-trainingにおいて共同最適化されていない別個のスキルであることを示しています。
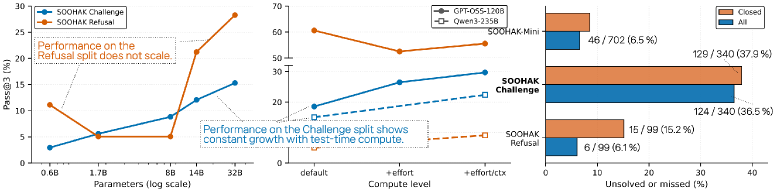
compute scalingのパネルでは、Qwen3 0.6B–32Bにわたって、ChallengeとRefusalの両方でパラメータ数の増加に伴いPass@3が上昇することが示されています。また、GPT-OSS-120BのTest-time scaling(medium 16kトークン;hard 16k;hard 81{,}920)は単調な改善をもたらしており、Soohakがいずれの次元でもまだ飽和していないことを示しています。
人間のベースライン
5名×5チーム(CS専攻IMO経験者;数学専攻IMO経験者;数学専攻IMO金メダル;数学専攻;数学研究者)が、79問のサブセット(キャリブレーション49問、Challengeからアップサンプリング30問)に対して4.5時間の制限内で挑戦し、CAS、プログラミング、非AIの検索ツールの使用が許可されました。モデルは同じ79問に対してPass@1を受け取りました。
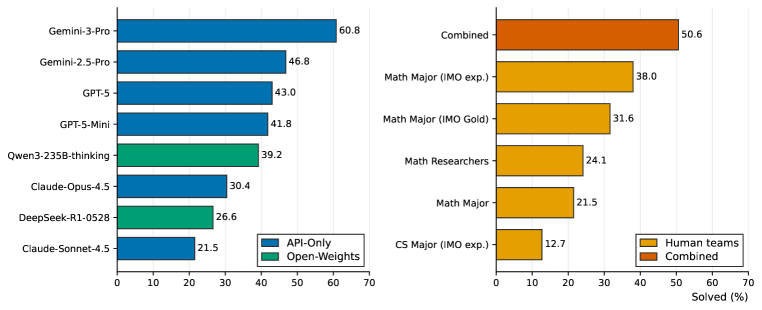
Gemini-3-Proのみが50.6%で人間チームの合計カバレッジを上回っています。最強の単一チームは数学専攻(IMO経験)チームです。数学研究者(チームE)は、このセットにおいてIMOトレーニングを受けた学部生を凌駕しておらず、これはベンチマークのオリンピック色の強い問題と研究色の強い問題の混合と一致しています。
限界と未解決の問題
- セッションは人間チーム間で標準化されておらず、フロンティア難易度での分散が増加しています。
- テキストのみのLaTeXによる純粋な結果ベースのスコアリングは、図を必要とする問題や真に未解決の予想を除外しており、ここでの「研究レベル」とは検証可能な最終解答を持つ難問を意味し、真の未解決数学を意味するものではありません。
- Challengeゲートはトップのクローズドシステムに対して意図的にそれほど厳しく設定されなかったため、Gemini-3-ProとGPT-5にとってのヘッドルームが一部犠牲にされています。
- Refusal性能はChallengeの解答能力と相関しませんが、ベンチマークはキャリブレーショントレーニングと真の不適切設定検出をまだ切り分けられていません。
重要性
Soohakは、フロンティアシステムを統計的に分離するのに十分な問題数(採点済み439問、Miniに702問追加)を持つ最初の研究レベル数学ベンチマークを提供し、最良のモデルでもAvg@3で30%という大きなギャップを明らかにします——これはオリンピックベンチマークがもはや明らかにできないことです。Refusalスプリットは、先行ベンチマークが無視してきた研究スキルを形式化し、解答と拒否のランク逆転はpost-trainingにおける未開拓の次元を示しています。
Source: https://arxiv.org/abs/2605.09063
Geometry Conflict: LLMの継続的ポストトレーニングにおける忘却の説明と制御
問題設定
LLMの継続的ポストトレーニングでは、更新 \Delta_t = \theta_t - \theta_{\text{pre}} を通じて、新しいドメイン・スキル・振る舞いを逐次的に注入します。既存の手法(逐次SFT、EWC、replay(FOREVER)、task-arithmeticによるmerging(TIES、DARE、AIMMerging))は忘却を緩和するものの、新しい更新がクリーンに転移するか、あるいは既習の能力を上書きするかを判断する原理的な基準を提供していません。どの更新をどの重みでどの層にmergeするかといった実践的な意思決定は、試行錯誤に頼っています。本論文は、忘却が更新と変化し続けるモデル状態との相対的な幾何学的特性によって支配されると主張し、その診断をデータフリーなmergingアルゴリズム(GCWM)へと昇華させます。
忘却を支配するもの
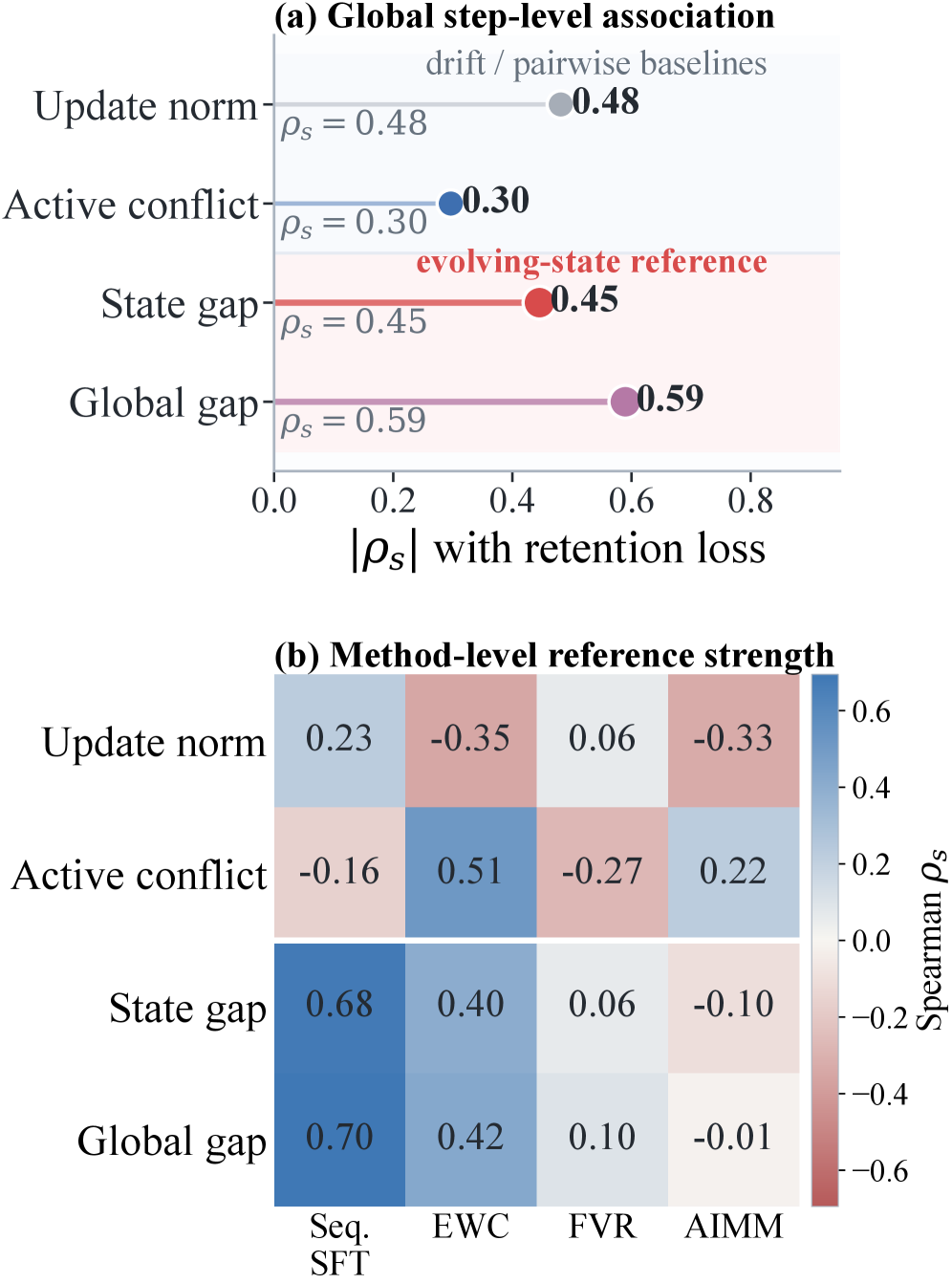
著者らは各タスクの更新を層ごとの共分散 C_i^{(\ell)} = (\Delta_i^{(\ell)})^\top \Delta_i^{(\ell)} + \lambda I で表現し、逐次SFT・EWC・FOREVER・AIMMerging下においてQwen3(0.6B〜14B)全体でリテンション損失の予測候補として、更新ノルム、部分空間アライメント比(SAR)、gradient conflict、そしてアクティブな更新間およびモデルの現在状態に対するBures–Wassersteinの「geometry conflict」の4つを比較します。
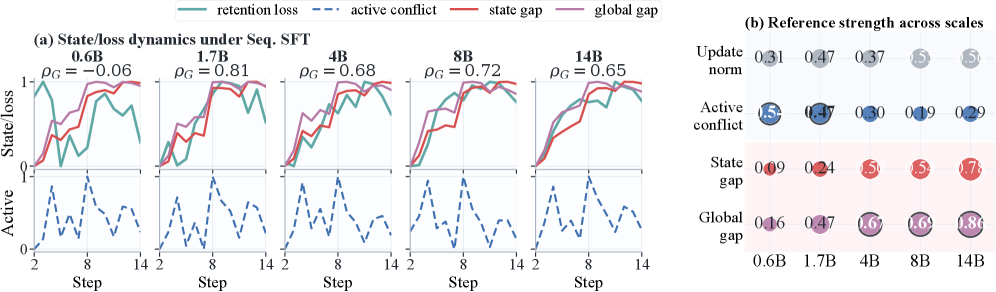
実験的な知見として、更新ノルムはSpearman相関でリテンション損失との粗い信号(|\rho_s|=0.48)のみを与え、pairwiseなアクティブconflictはさらに弱い(|\rho_s|=0.30)ものの、state-relativeなギャップ — 新しいアクティブな更新の幾何と蓄積されたモデル状態の幾何との不一致 — はグローバルで |\rho_s|=0.59 に達し、0.6Bの 0.16 から14Bの 0.86 まで単調増加します。つまり、忘却は「パラメータがどれだけ動くか」ではなく、「その動きが過去の更新によって既に符号化された幾何とどれほど相容れないか」によって決まります。
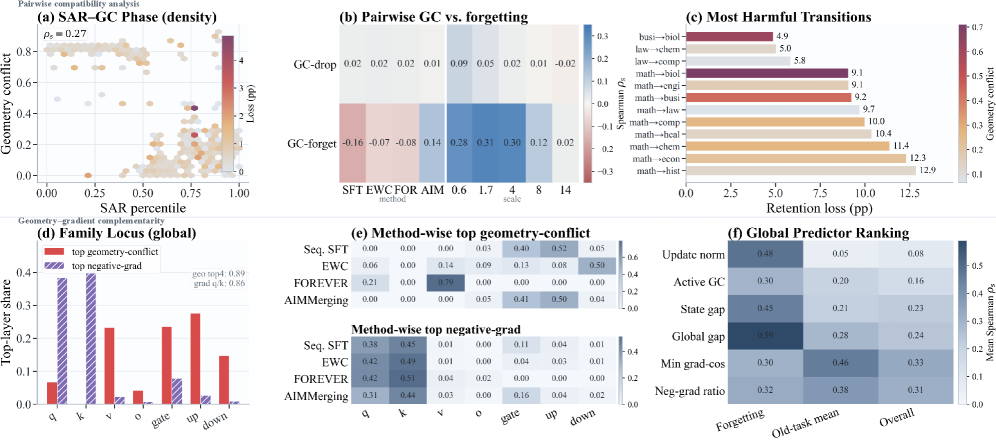
補完的な層別分析(Fig. 3)では、SARとgeometry conflictが組み合わさることでタスクペアを異なる転移レジーム(正の転移・中立・干渉)に分類できる一方、gradient conflictは上位層のパラメータ共有に集中した異なる失敗モードを捉えることが示されます。したがって、geometryとgradient conflictは冗長ではなく補完的な関係にあります。
GCWM:診断をコントローラへ変換する
GCWMは、アクティブなタスクベクトルのみでパラメータ化されたデータフリーなmergingの手順です。各線形層 \ell において以下を実行します。
- 切り詰めSVD \Delta_i^{(\ell)} \approx U_i \Sigma_i V_i^\top を計算し、共有右特異基底 Q^{(\ell)} = \mathrm{orth}([V_1^{(\ell)},\dots,V_m^{(\ell)}]) を構成します。
- 各更新の共分散を共有基底に射影します:B_i^{(\ell)} = (Q^{(\ell)})^\top C_i^{(\ell)} Q^{(\ell)}。
- Pairwiseな正規化Bures–Wasserstein conflictを計算します。 \gamma_{ij}^{(\ell)} = \frac{d_B^2(B_i^{(\ell)}, B_j^{(\ell)})}{\mathrm{tr}(B_i^{(\ell)}) + \mathrm{tr}(B_j^{(\ell)}) + \varepsilon},\quad d_B^2(A,B)=\mathrm{tr}(A)+\mathrm{tr}(B)-2\,\mathrm{tr}((A^{1/2}BA^{1/2})^{1/2}).
- 層スコア g^{(\ell)} = \sum_{i<j} w_{ij}\gamma_{ij}^{(\ell)} に集約し、シグモイドゲートへ変換します。 \alpha^{(\ell)} = \alpha_{\min} + (\alpha_{\max}-\alpha_{\min})\,\sigma(\kappa(g^{(\ell)} - \tau)).
ステップ t において、\alpha^{(\ell)} で変調されたmerge済み更新の差分部分のみが適用されます。高conflict層では幾何認識型の補正が強くかかり(mergingを互換性のある方向に実効的に縮小)、低conflict層はそのまま通過します。この構成はclosed-formであり、replay データ・ヘルドアウト評価・gradient へのアクセスを一切必要とせず、タスクベクトルのみを用います。
結果
Qwen3バックボーンにおけるドメイン継続的なMMLU-Pro(14サブドメイン、各1kサンプル)では、GCWMがマルチタスク合同学習とのギャップをほぼ埋めることが示されます。
- 1.7B:MTL上限 44.4 → 逐次SFT 36.8、EWC 40.0、AIMMerging 41.8、OPCM 41.7、GCWM 43.5
- 8B:MTL 65.3 → 逐次SFT 55.2、AIMMerging 62.9、OPCM 61.9、GCWM 63.7
- 14B:MTL 68.6 → 逐次SFT 60.4、AIMMerging 66.4、OPCM 66.6、GCWM 67.8
GCWMは全てのブロックで最良の非MTL手法であり、8Bでは逐次SFTに対して最大の改善(+8.5ポイント)、スケール全体で最強のデータフリーベースライン(OPCM/AIMMerging)に対して 0.8〜1.8 ポイントの改善を達成します。ドメイン別では、GCWMは従来干渉が生じやすいカテゴリ(8BのCS:64.7 対 OPCM 62.8;14BのHist:OPCMと高精度で一致)で競争力を持ち、ゲートが均一な縮小ではなく有用な層ごとの変調を行っていることが示唆されます。
限界と未解決の問題
共分散 C_i^{(\ell)} = (\Delta^{(\ell)})^\top \Delta^{(\ell)} はタスク誘発の幾何の粗い代理指標であり、真のFisher情報はデータを要します。切り詰めSVDによる共有基底と、閾値 \tau、鋭さ \kappa、ランク m はハイパーパラメータであり、本文中でその感度は定量化されていません。state-relativeな分析は相関的なものであり、|\rho_s| が最大 0.86 に達するものの因果メカニズムではありません;MTLとのギャップは依然として 0.8〜1.6 ポイント残っており、純粋な更新幾何だけでは埋めきれない余地が存在します。能力継続学習(数学 vs. コード)の結果は言及されているものの、上記には示されていません。更新幾何がよりノイズが多くポリシー状態と結合したRLポストトレーニングにまでgeometry conflictが一般化するかどうかは未解決のままです。
なぜ重要か
現在の継続的ポストトレーニング研究の多くは、忘却をreplayや正則化によって償却すべき不可避のコストとして扱っています。本論文はこれを、入力される更新と変化し続けるモデル状態の間の測定可能な幾何学的非互換性として再定式化し、同じ量が効果的な層ごとのゲーティング信号として機能し、データ・gradient・replayなしに合同学習の精度のほとんどを回復できることを示します。これにより、更新の統合は経験的な運任せではなく、制御可能で予測可能な操作となります。
Source: https://arxiv.org/abs/2605.09608
大規模言語モデルにおけるモデルマージのスケーリング則
問題設定
モデルマージ — fine-tuned チェックポイントの平均化やタスク算術的な組み合わせ — は、マルチタスク SFT に対する低コストな代替手法ですが、専門家を追加したりベースモデルをスケールアップしたりする際のリターンについて、定量的なルールを持つ実践者はいません。9番目の専門家をマージすべきか、それとも大きなバックボーンを訓練すべきか。限界的な改善がノイズ以下に落ちるのはいつか。本論文は、マージされた LLM のクロスエントロピーに対する経験的スケーリング則を、ベースサイズ N と専門家数 k の同時関数として提供し、4種類のマージルールと7つのバックボーンサイズにわたって検証し、1/k の裾野を説明する小規模な理論モデルを導出します。
セットアップと法則
各バックボーン N \in \{0.5, 1.5, 3, 7, 14, 32, 72\} B(Qwen-2.5 ファミリー、合計10,866チェックポイント)について、著者らは代数、解析、幾何、離散数学、数論、コード、化学、物理、生物学をカバーする M=9 のドメイン特化専門家を訓練します。マージルール(Average、TA、TIES、DARE)とターゲットサブセットサイズ k \in \{1,\ldots,9\} に対して、\binom{M}{k} 個のすべてのサブセットまたは均一サンプルを評価し、経験的条件付き期待値を次のように形成します。
\widehat{\mathbb{E}}[L\mid N,k] = \frac{1}{S_{N,k}} \sum_{s=1}^{S_{N,k}} L(N,k,s).
サブセットごとの loss はノイズを持ちますが(散布図のバンドとして可視化される)、k ごとの平均は逓減するリターンを持つ滑らかな単調曲線です。

中心的な経験的主張は、この期待値がフロアプラス裾野の法則に適合するというものです。
\mathbb{E}[L\mid N,k] = L_\infty(N) + \frac{A(N)}{k+b},\qquad b \ge 0\ \text{small}.
L_\infty(N) はより多くの専門家がマージされた際の漸近値(そのバックボーンサイズでマージルールが回復できる最良値として解釈される)であり、A(N)/(k+b) はマージの裾野です。これはドメイン内評価(ドナー自身のドメインでの評価)とクロスドメイン評価(9つすべてのマクロ平均)の両方で成立します。この法則は Average、TA、TIES、DARE に対して同一の関数形で適用でき、係数のみが変化します。
2つの規則性が直接導かれます:(i) 1/(k+b) は小さい k において急激に減少するため、大部分の改善は初期に得られること、(ii) より多くのドナーにわたる平均化がランダムサブセット分布をその平均の周りに集中させるため、サブセットレベルの分散は k が増加するにつれて縮小すること。Figure 3 のパネル5はこの収縮を代数において明示的に示しています。
理論的スケッチ
著者らの理論は、マージされたパラメータを有界なペアワイズ干渉を持つ k 個のタスクベクトルの均一平均としてモデル化します。ベースモデル周りの loss に対する緩やかな正則性のもと、二次展開によって均一 k-サブセットにわたる期待値が 1/k でスケールする超過 loss 項が得られ、b が有限 k の補正を吸収する A(N)/(k+b) の裾野が再現されます。L_\infty(N) は、k ではなくバックボーンとドナープールに固有の特性である、ベースモデルの曲率と残差クロスドメインミスマッチとして同定されます。
定量的挙動とプールサイズ分析
フロア L_\infty(N) は N に対して厳密なべき乗則に従い、ドナープールに M=8 または M=7 の利用可能なドメインがあるかどうかにほぼ依存しません。プールサイズの効果は裾野 A(N) に集中しています:M=8 から M=7 に移行すると、化学・物理では A(N) が N に対してフラットから減少傾向になる一方、数学系ドメインはほとんど変化しません。解釈としては、より多様なプールが相補的なドナーを供給し、A(N)/(k+b) 項における残差クロスドメインミスマッチを抑制すること — これは中程度から大きな k および大きな N で最も顕著に現れます。フロアはバックボーンによって決まり、裾野はドナーの多様性によって決まります。
フィットされた法則はまた、著者らが提唱する計画のためのレバーを提供します:それを逆算してターゲット loss に到達するために必要な k を推定し、A(N)/(k+b) が許容値以下に落ちる停止点を検出し、固定計算量予算のもとで N のスケールアップと専門家の追加を比較します。専門家のポストトレーニング自体も N とポストトレーニング計算量に対して別のスケーリングパターンに従うため(論文の Figure 11)、マージ則はエンドツーエンドの予算策定のために専門家側のスケーリングと整合的に組み合わせられます。
限界とオープンクエスチョン
- グリッドは単一ファミリー(Qwen-2.5)かつ単一タスクの種類(数学・科学・コードのドメイン)であり、フロアの N に対するべき乗則は、評価が純粋な CE でないマルチモーダルや instruction-following の loss には一般化しない可能性があります。
- M=9 は小さく、1/(k+b) の形式は k=9 までしか検証されておらず、漸近値 L_\infty(N) は測定ではなく外挿です。
- 理論はタスクベクトル間の有界なペアワイズ干渉を仮定しており、病理的なマージルールや強く競合する専門家(例:敵対的 fine-tune)はこれに違反します。
- サブセットレベルの分散は認識されていますが、モデル化されていません — この法則は平均を予測するため、リスク敏感なデプロイメントには依然として別個の分散推定器が必要です。
- CE ではなくダウンストリームメトリクス(accuracy、pass@1)に対して同一の法則が成立するかどうかの分析はありません。
なぜこれが重要か
マージに対する予測的な2パラメータ法則は、「いくつかの組み合わせを試す」という作業を計画問題に変換します:ベースサイズとドナープールが与えられれば、専門家を一切訓練する前に k 人の専門家で到達可能な loss を推定し、限界計算量を N の拡大とドナーの追加のどちらに費やすべきかを判断できます。これにより、マージはヒューリスティックなショートカットではなく、マルチタスク SFT と定量的に比較可能な代替手法となります。
Source: https://arxiv.org/abs/2509.24244
G-Zero: ゼロデータからの Open-Ended Generation のための Self-Play
問題設定
R-Zero のような自己進化型 LLM パイプラインは、多数決投票やルールベースの検証器に依存しており、これらは数学やユニットテスト付きのコードといった閉じた検証可能なドメインでしか機能しません。open-ended な生成への self-play の拡張は、通常 LLM-as-a-judge に頼ることになりますが、そのスカラースコアは judge 自身の能力に上界が制限され、報酬ハッキング(長さバイアス、sycophancy、文体的な抜け穴)に対して脆弱であることが広く知られています。G-Zero は、訓練対象モデル自身の内部分布から完全に生成される代替の監督信号を提案し、外部の検証器や judge をループから取り除きます。
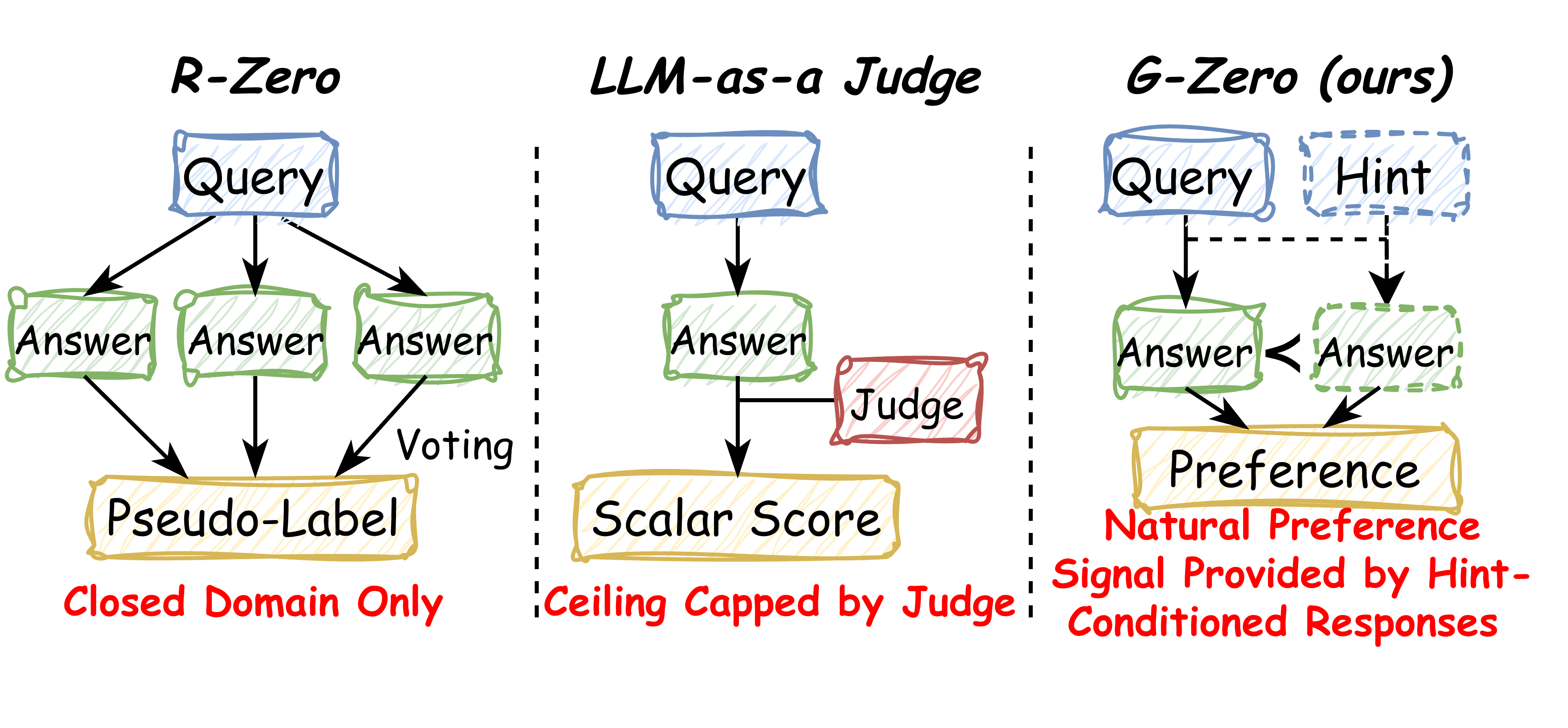
手法
G-Zero は、Proposer \pi_P と Generator \pi_G の間の二プレイヤー共進化ループであり、Hint-\delta と呼ばれる単一の内的スカラーによって結合されています。
Hint-\delta。 クエリ q、Proposer が生成したヒント h、およびトークン列 (a_1,\dots,a_T) を持つ Generator のヒントなし応答 a_{\text{hard}} \sim \pi_G(\cdot \mid q) に対して、
\delta(q,h,a_{\text{hard}}) = \frac{1}{T}\sum_{t=1}^{T}\Big[\log\pi_G(a_t\mid q, a_{<t}) - \log\pi_G(a_t \mid q, h, a_{<t})\Big].
これは、h を先頭に付加したときに \pi_G 自身のヒントなし軌跡に誘起されるトークンあたりの平均対数尤度低下です。系列の総和ではなくトークンあたりの正規化が重要な設計上の選択であり、1,824 サンプルの R1 プールにおいて \delta と |a_{\text{hard}}| の間の Spearman 相関は -0.41 となり、明らかな長さ利用チャネルが塞がれています。大きな \delta が得られるためには、a_{\text{hard}} が不確実または誤りを含む(難しいクエリ)ことと、h が \pi_G の次トークン分布を真に再編成する情報を含む(情報量の多いヒント)ことの両方が必要です。
Proposer フェーズ。 \pi_G を固定した状態で、\pi_P は (q_i, h_i) のペアをサンプリングし、\delta を報酬として GRPO によって更新されます。これにより Proposer は Generator の盲点、すなわち \pi_G が誤りを犯しているが少量の誘導を与えれば回復可能な領域へと誘導されます。
Generator フェーズ。 \pi_P を固定した状態で、Generator は各 q_i に対してヒントあり・なしの両方で回答します。\delta パーセンタイルフィルタが、ラウンド R の preference データセット \mathcal{D}_{R+1} にペアを選択します。ここで a(ヒントあり)が chosen 応答、a_{\text{hard}} が rejected 応答となります。その後 \pi_G は DPO によって更新されます。推論時にはヒントは除去されます。Generator は構造的な改善を内面化し、h に依存してはなりません。
著者らは、二つの条件のもとで理想化された標準 DPO 変形に対する最良反復準最適性境界を証明しています。それは (i) Proposer がクエリ・ヒント空間上で十分なカバレッジを誘起すること、および (ii) \delta フィルタが擬似ラベルノイズを低く保つことです。どちらの仮定も実際には自明ではありませんが、フィルタの役割を明確にしています。フィルタは単なるデータの品質管理ではなく、収束のための前提条件です。
結果
実験では Qwen3-8B-Base と Llama-3.1-8B-Instruct を使用しており、意図的に異なるファミリーの基盤モデルと aligned 命令モデルを網羅しています。
最も有益な分析は、ループがどのようなデータを選択するかに関するものです。Qwen3-8B-Base(ラウンド 1)における \delta フィルタリング後、DPO プールの数学は 9.6%、コードは 9.0% に過ぎず、大部分はアドバイス(30.2%)、その他(24.1%)、ライティング(17.4%)、説明(9.6%)が占めています。平均 \delta 値は数学(0.045)ではなく、ライティング(0.060)と説明(0.058)で最も高くなっています。それにもかかわらず、[0,50] パーセンタイルフィルタ(G-Zero のデフォルト)のもとで、モデルは数学が 8.81 から 11.78(絶対値)、Chat が 8.94 から 9.07、IFEval が 52.78 から 53.03、平均が 33.95 から 34.96 へと改善しています。推論の向上は、ドメイン内の数学的記憶からではなく、検証不可能なカテゴリで引き出された合成パターンの構造的転移から生じています。
フィルタのアブレーションは設計が自明でないことを示しています:[0,50] では平均 34.96、[20,80] では 34.40、[50,100] では 34.04、フィルタなしの [0,100] では 34.65 となっています。高 \delta 側の裾だけでは低・中程度の範囲より悪くなっており、極端な \delta 値はノイズの多い擬似ラベル(改良ではなく上書きするヒント)であるという理論と整合しています。
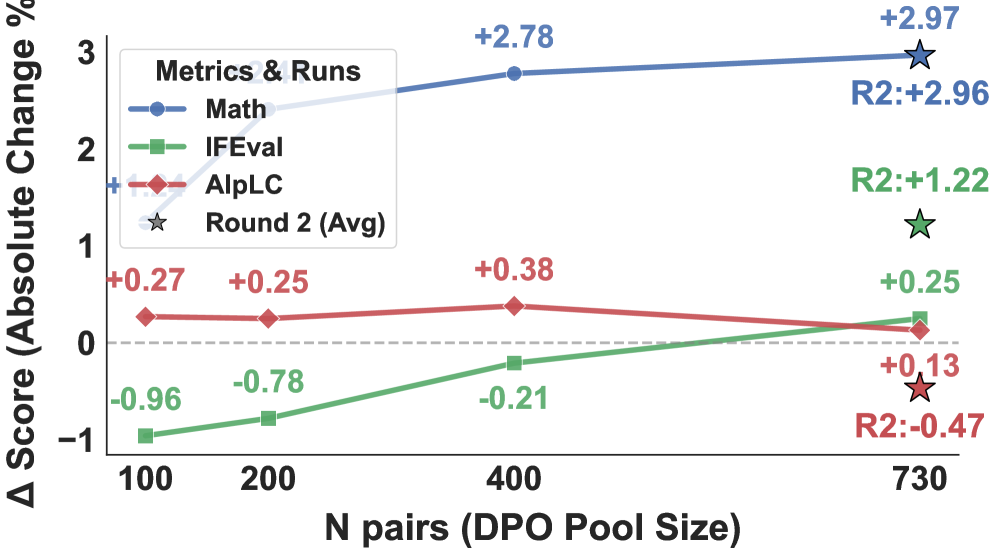
図 3 は DPO プール(N \in \{100, 200, 400, 730\})の増分スケーリングを示しており、ラウンド 2 のゼロからの実行が N=730 の参照点としてプロットされています。これは、反復的な改良が単一のより大きなプールによる実行で達成できるものを超えて累積することを示唆しています。
限界とオープンクエスチョン
Hint-\delta は自己参照的な信号です。\pi_G 自身の分布のシフトを測定しており、\pi_G を分布外に単純に押し出すような病理的なヒントは、正しくなくても高いスコアを得る可能性があります。また収束保証は、パーセンタイルフィルタリングによって経験的に強制されているものの検証されていない「低擬似ラベルノイズ」条件に依存しています。本論文は多ラウンド後の挙動を報告しておらず、Generator が Proposer の引き出せるすべてを吸収した後に \delta が崩壊するのか、あるいは Proposer が新たな盲点を見つけ続けるのかは不明です。また、同一プールに対する強い LLM-as-a-judge ベースラインとの比較もないため、「外部 judge 不要」という利点の大きさは定量化されていません。最後に、両モデルとも 8B であり、\pi_G がはるかに強力な場合(ヒントによる対数確率シフトが縮小する場合)に Hint-\delta が識別力を保てるかどうかは未解決です。
なぜこれが重要か
G-Zero は外部のスカラー報酬を内部の分布的シフトで置き換えており、これは構成上検証器不要かつ長さ不変です。スケールにおいて収束挙動が成立するならば、RLAIF スタイルのパイプラインのボトルネックとなってきた judge 能力の上界なしに、open-ended タスクに対する継続的な post-training への道を提供します。
Source: https://arxiv.org/abs/2605.09959
CollabVR: 視覚言語モデルと動画生成モデルによる協調的動画推論
問題設定
「動画で思考する(Thinking with Video)」とは、動画生成モデル(VGM)を推論の基盤として扱うアプローチです。このアプローチでは、モデルがトークンを出力する代わりに、Chain-of-Frames(CoF)——目標指向タスク(手順的な操作、ナビゲーション、多段階の物理シミュレーション)における中間的な推論状態としてフレームが機能する、時間的に一貫したクリップ——を出力します。強力なVGMは言語で表現しにくい短時間スケールの視覚的ダイナミクスを内部に取り込んでいるという点が魅力です。しかし、失敗パターンは明確です:
- 長期的な目標の逸脱(Long-horizon drift)。 複数のサブゴールを必要とするタスクでは、VGMの暗黙的な計画が劣化し、後半のフレームは局所的な連続性は満たすものの、全体的な目標に違反するようになります。
- クリップ中間でのシミュレーション誤り。 単一の生成クリップ内で、モデルが物理的または意味的に矛盾した遷移を起こし、その破損した状態を条件として処理を継続するため、誤りが累積していきます。
どちらの問題も構造的な原因を共有しています。すなわち、VGMが実際に推論を行う粒度(数秒のフレーム)で機能する明示的な熟慮プロセスが存在しないことです。視覚言語モデル(VLM)はその熟慮を提供する自然な候補ですが、どこに配置するかという問題は自明ではありません。事前のVLM計画はピクセルが存在する前にコミットしなければならないため、VGMの固有の失敗パターンに対して盲目的になります。一方、長い動画全体に対する事後的な批評は、誤りがすでに連鎖した後に介入することになります。
手法
CollabVRはクローズドループのステップレベルコントローラーであり、クリップ粒度でVLMとVGMを交互に機能させます。VGMを現在の終端フレームとアクションプロンプト a_t から短いクリップ c_t を生成する条件付き生成器 G(\cdot \mid \text{frame}_{t}, a_t) とします。VLMは2つの役割を担います:プランナー \pi(a_t \mid \text{goal}, h_{<t}, \text{frame}_t, d_{t-1}) と、クリップを検査して二値の受理判定 s_t および検出された失敗(物体の消失、誤った接触、制約違反、サブゴールからの逸脱)を説明する診断文字列 d_t を返す検証器 v(c_t, a_t) \to (s_t, d_t) です。
各ステップ t におけるループの処理:
- 計画(Plan)。 VLMがゴール、それまでに受理されたクリップの要約 h_{<t}、現在の終端フレーム、および直前の診断 d_{t-1} を条件として、次の即時アクション a_t を出力します。
- 生成(Generate)。 VGMが c_t = G(\text{frame}_t, a_t) を生成します。
- 検証(Verify)。 VLMが c_t を a_t およびグローバルゴールと照合して検査し、(s_t, d_t) を出力します。
- 修復またはコミット(Repair or commit)。 s_t = 0 の場合、次の計画呼び出しで d_t を使用して a_{t+1} を書き直す(または修正的な表現で a_t を再試行する)。s_t = 1 の場合、c_t を軌跡に追加し、\text{frame}_{t+1} は c_t の最後のフレームとなります。
重要な設計上の決定は、検証器の診断をグローバルなロールバックのトリガーとするのではなく、次のアクションプロンプトに直接折り込む点です。これにより、VGMが得意とする短時間スケールの領域で動作し続けながら、VLMが最も強みを発揮する長期的な推論を行えるようにしています。計算量は、VGMの総forward passの数を基準としてベースラインと比較されており、再試行はPass@kや単純なtest-time scalingが消費する分の代替となり、追加ではありません。
結果
Gen-ViRe および VBVR-Bench において、CollabVRは計算量を揃えた条件下で、オープンソース・クローズドソースを問わず複数のVGMを、(a) 単一推論、(b) VLMジャッジによるPass@k選択、(c) 従来のtest-time scalingベースラインに対して改善しました。報告されたパターンは一貫しており、タスクの難易度が上がるほど改善幅が大きく、最も困難な長期ホライズンのサブセットで最大の改善が見られました。クローズドループのステップレベル結合は、事前計画アブレーションおよび事後批評アブレーションを上回り、検証器の診断をアクションプロンプトに折り込むことの貢献——単にパイプラインに検証器を持つこととは区別して——を孤立して示しています。
(各ベンチマークの具体的な改善幅は論文の表に報告されており、アブストラクトでは最も困難なタスクで改善が最大になることが強調されています。これは失敗モードの分析と一致しています:逸脱とクリップ中間での誤りの累積は、候補分布が同じ系統的なバイアスを共有しているためPass@kでは対処できないまさにその状況です。)
限界と未解決の問題
- 検証器の能力の上限。 ループの修復品質は、VLM検証器がクリップ中間のシミュレーション誤りを検出する能力に依存します——これは現在のVLMが弱いと知られている領域(微妙な物理違反、細粒度の物体状態変化)です。検証器が見逃した失敗は伝播します。
- ステップ粒度が固定されている。 「ステップ」を定義するクリップの長さはハイパーパラメータとして扱われており、適応的なセグメンテーション(検証器が検出したサブゴール境界でコミットする)は探索されていません。
- レイテンシ。 ステップごとのVLM呼び出しにより推論パスが2倍になります。計算量揃えの比較はVGMのコストを制御していますが、VLMとVGMが異なるアクセラレータで実行される場合のwall-clock timeは制御されていません。
- gradient フィードバックなし。 診断はプロンプトを通じてのみ機能します。構造化された検証器の出力を条件とするVGMの学習(またはループの蒸留)は未解決です。
- 検証器とプランナーの共通の失敗モード。 同じVLMをプランナーと検証器の両方として使用することで、相関した盲点が生じるリスクがあります。非対称なペアリングは研究されていません。
なぜ重要か
CollabVRは、「動画で思考する」アプローチが最も効果的になるのは、VGMを単独の長期ホライズン推論器としてではなく、外部の熟慮プロセスがステップバイステップでその出力を消費する短時間スケールのシミュレータとして扱う場合であることを示しています。クリップ粒度で検証し、診断を次のアクションプロンプトに反映するという設計上の処方箋は、どちらのモデルも再学習することなく将来の動画推論システムが採用できる、具体的かつ計算量揃えのレシピです。
Source: https://arxiv.org/abs/2605.08735
TMAS: マルチエージェントの協調によるTest-Time Computeのスケーリング
問題設定
構造化されたtest-time scalingは、2つの補完的な軸に収束しています。すなわち、並列サンプリング(self-consistency、best-of-N)と逐次的な改善(self-refine、verify-refine)です。並列軸上の手法は軌跡をi.i.d.サンプルとして扱い、事後的に集約するため、軌跡間のシグナルが活用されません。逐次軸上の手法は、生の履歴または軽く要約した履歴を条件として改善を行いますが、これにより信頼性の高い部分的な進捗とノイズの多い誤った推論が混在し、使い果たした戦略の再探索を回避する明示的なメカニズムが存在しません。その結果、探索と活用のバランスが悪くなります。すなわち、同じ失敗したアプローチの冗長なロールアウトか、欠陥のある部分的解への早期のコミットメントかという問題が生じます。TMASは、困難な数学ベンチマーク(IMO-AnswerBench-50、HLE-Math-100)においてこのギャップを標的としています。これらのベンチマークでは、単一のPass@1軌跡が成功することはほとんどなく、素朴なスケーリングは飽和してしまいます。
手法
TMASは推論を5エージェントのパイプラインとして構成し、2種類の型付きメモリバンクを通じて調整を行い、最大20イテレーションを実行します。
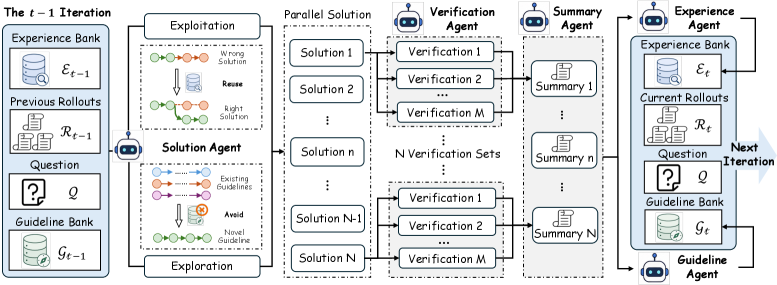
各エージェントは以下の通りです。
- Solution agents — 問題と両方のメモリバンクの現在の内容を条件とする N=8 の並列ソルバー。
- Verifier agents — 局所的な正確性判断を生成してエラーを特定する、軌跡ごとに M=8 の独立したベリファイアー。複数のベリファイアーを使用することで、従来のverify-refine手法を悩ませる単一ベリファイアーのノイズが低減されます。
- Summarizer agent — 各(軌跡、ベリファイアーバンドル)をロールアウトレベルの要約に蒸留します。
- Experience agent — エクスペリエンスバンクに低レベルのエントリを書き込みます。内容は、検証済みの中間補題、機能した具体的な手法、ベリファイアーが指摘した落とし穴です。これらは次のイテレーションで再利用されることを意図しています。
- Guideline agent — ガイドラインバンクに高レベルのエントリを書き込みます。内容は、すでに試みた戦略的方向性です。これらは次のイテレーションで回避されることを意図しており、非冗長な探索を強制します。
2つのバンクの非対称性が重要な設計選択です。エクスペリエンスバンクは活用メモリ(サブ問題レベルで信頼性の高いものを再利用する)であり、ガイドラインバンクは探索メモリ(戦略レベルで試みたものを否定する)です。探索係数 \epsilon=0.2 は、後続のソルバーへのプロンプト時における2つのバンクの混合を制御し、部分的な進捗の再利用と多様化のバランスを取ります。
ベースモデルはQwen3-30B-A3B-Thinking-2507とQwen3-4B-Thinking-2507であり、最大出力128K、温度1.0、top-p 0.95です。4BバリアントはさらにマルチタスクのRLステージを経ます。著者らは、vanilla正解性のみのrewardと、エージェントをその役割全体にわたって共同でスコアリングするhybrid reward(検証品質、要約忠実度、メモリの有用性)を比較しています。これにより、システムは5つの独立して訓練されたポリシーとしてではなく、協調したユニットとして最適化されます。訓練にはバッチサイズ128、16ロールアウト/プロンプト、80Kトークンのレスポンス、学習率 1\times 10^{-6} を使用し、FP8ロールアウト量子化を適用した256台のH20 GPU上で実行されます。
結果
主要な挙動は、hybrid-RL訓練が逐次的な改善において vanilla RLが引き起こす飽和・性能低下を防ぐというものです。
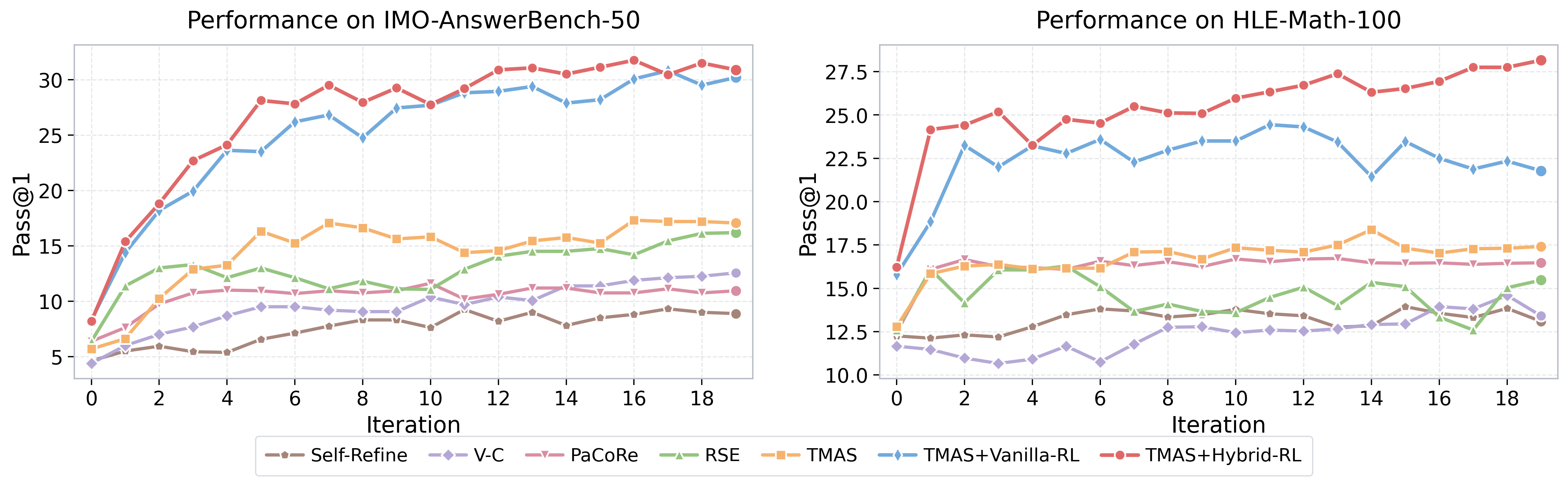
vanilla-RLの曲線は、改善訓練でよく知られた病理を示しています。ポリシーがシングルショットの正確性に過学習し、メモリチャネルを無視することを学習するため、追加のイテレーションはコストを増やすだけで精度が向上しません。hybrid-rewardの曲線は高い値から始まり、20イテレーションの予算全体にわたって単調に上昇し続けます。これは、エージェントごとのrewardがベリファイアー、サマライザー、メモリ更新エージェントを情報量のある状態に保っていることを示しています。
感度分析では、3つの主要なハイパーパラメーターを分離しています。
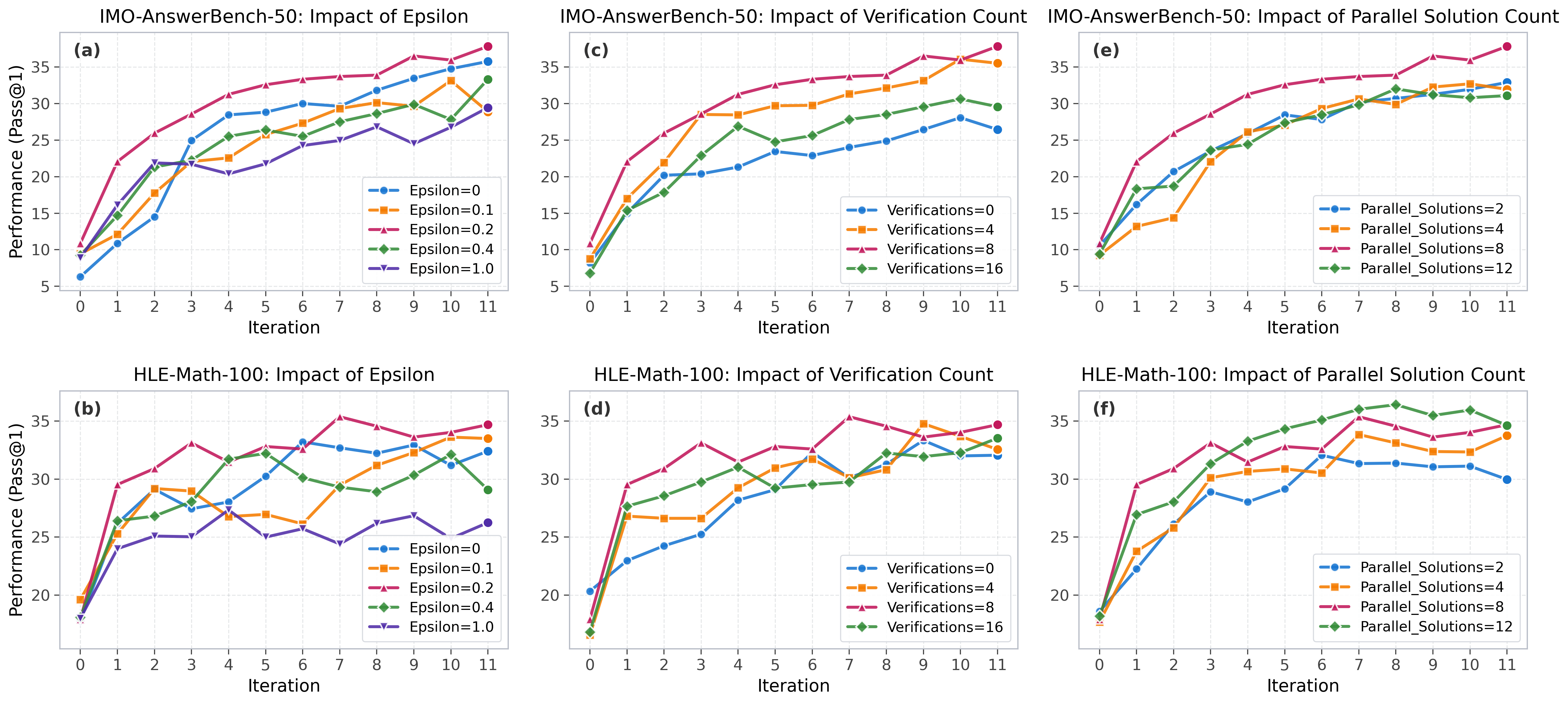
探索係数は \epsilon=0.2 付近でピークを迎えます。小さすぎると単一の攻め方の活用に崩壊し、大きすぎるとガイドラインバンクの回避シグナルが再利用可能なエクスペリエンスを圧倒します。ベリファイアー数 M と解数 N はともに8を超えると収穫逓減を示し、 N=M=8 という設定が正当化されます。IMO-AnswerBench-50およびHLE-Math-100上でのMV、Self-Refine、Verify-Refine、PaCoRe、RSEに対する完全な数値比較が本論文の主要な実験的主張であり、AIME26とHMMT-25-Novの数値は付録で報告されています。これらのベンチマークは、考慮されたQwen3ベースモデルにとってほぼ飽和状態にあるためです。
限界と未解決の問い
計算フットプリントは無視できません。各イテレーションは N \cdot(ソルバー)+ N \cdot M \cdot(ベリファイアー)+ サマライザー + 2回のメモリ更新を消費し、予算は20イテレーションです。Pass@1の改善は、この乗算的なコストと比較検討する必要があります。本論文は、同等の計算量における調整済みbest-of-N ベースラインと比較した総トークン数に対する精度のプロットを示していないようです。hybrid rewardの分解は定性的に説明されており、正確なエージェントごとのrewardシェーピングと、エージェントごとのground truthなしにどのようにクレジットを割り当てるかが、再現性において最も重要な部分です。ガイドラインバンクの「回避」セマンティクスは、ソルバーが実際に否定的な指示に従うことに依存しており、小さいモデルでは脆弱です。最後に、評価は数学に限定されています。エクスペリエンス/ガイドラインの分割が、明確なベリファイアーのない領域(証明、コード、曖昧なground truthを持つ科学的QA)に転移するかどうかは未解決のままです。
なぜ重要か
TMASは、test-time scalingが単により多くのトークンを消費するのではなく、ロールアウト間を流れる情報を型付けすべきであるというアイデアの、明確な具体化です。すなわち、再利用可能なサブ結果を使い果たした戦略から分離するということです。hybrid-RLの結果は、エージェントを意識したrewardが逐次的なシステムにおいて単一目的RLが引き起こす飽和を排除するという具体的なデータポイントであり、マルチエージェント推論スタックをエンドツーエンドで訓練する方法を示しています。
Source: https://arxiv.org/abs/2605.10344
SEIF: Self-Evolving Reinforcement Learning for Instruction Following
問題設定
Instruction followingはLLMのデプロイにおける依然としてボトルネックとなっています。モデルは、仕様化と検証が容易でありながら堅牢に学習することが難しい、複合的な制約(フォーマット、長さ、語彙の包含・除外、構造的ルール)を満たさなければなりません。主流の2つの学習レシピには既知の失敗モードがあります。人間または強力な教師のアノテーションを用いた教師ありパイプラインはコストが高く、教師の能力に上限が制約されます。一方、モデルが自ら生成した指示に従うよう学習するself-playアプローチは、指示の分布が難易度において静的であるため頭打ちになりやすいです。つまり、followerがシードの難易度を習得してしまうと、それ以上の学習シグナルが生成されなくなります。SEIFは、指示の難易度とfollowerの能力を単一のクローズドなRLループ内で共進化させることで、この頭打ち問題を解決しようとしています。
手法
SEIFは、同一のベースLLMから派生した4つの役割を実装します。
- Instructor \pi_I:明示的かつ検証可能な制約(フォーマット、キーワード、長さ、構造的制約)を持つ指示 x を生成します。
- Filter F:内部矛盾、仕様不足、または検証不可能な指示を除外し、保持された各 x に対して決定論的チェッカーが存在することを保証します。
- Follower \pi_F:応答 y \sim \pi_F(\cdot \mid x) を生成します。
- Judger J:制約ごとに r(x, y) \in \{0, 1\} を返し、スカラー報酬に集約するプログラム的検証器です。
学習は、同一のGRPOスタイルの目的関数を共有する2つのRLフェーズを交互に繰り返します。r を検証器由来の報酬、A をグループ相対的なadvantageとすると:
\mathcal{L}(\theta) = -\mathbb{E}\!\left[\min\!\big(\rho_\theta A,\ \mathrm{clip}(\rho_\theta, 1-\epsilon, 1+\epsilon) A\big)\right] + \beta\, \mathrm{KL}(\pi_\theta \| \pi_{\mathrm{ref}}),
ここで \rho_\theta = \pi_\theta(y\mid x)/\pi_{\mathrm{old}}(y\mid x) です。
Followerの更新。 フィルタリングされた指示のバッチが与えられると、\pi_F は標準的な検証器報酬 r_F = J(x, y) によって学習されます。これは従来のRLVRです。
Instructorの更新。 これがSEIFが従来のself-playと異なる点です。Instructorは、現在のfollowerにとって難しいが有効な指示を生成することに対して報酬を受けます。具体的には、各候補 x に対してinstructorは K 個のfollowerのロールアウト \{y_k\} をサンプリングし、以下の報酬を受け取ります。
r_I(x) = \mathbb{1}[F(x)=1]\cdot \phi\!\left(\tfrac{1}{K}\sum_k J(x, y_k)\right),
ここで \phi はfollowerの中間的な成功率(followerが \sim 30\text{-}70\% の確率で解ける指示)でピークを持ち、0 または 1 では抑制されます。これにより \pi_F を自動的に追跡するカリキュラムが生成されます。followerが向上するにつれて、以前は難しかった指示が飽和し、\phi が低下し、instructorは新たな制約の組み合わせへと向かうよう促されます。
2つの更新は交互に行われます。instructorの報酬が \pi_F の関数であり、followerの学習分布が \pi_I の関数であるため、このシステムは非定常なminimaxゲームの構造を持ち、グラウンドトゥルースとして機能する検証器 J によって安定化されます(学習済み報酬モデルを使用しないため、judger側での報酬ハッキングが発生しません)。
Filterは不可欠な要素です。instructorの探索はそれなしでは、病理的な制約(例:「20個のキーワードを含む正確に17語で応答せよ」)に崩壊してしまいます。これは満足不可能であり、followerの成功率を自明に低下させ、\phi が誤って高い報酬を与えてしまいます。F は制約一貫性チェックとLLMベースの充足可能性プローブを用い、いかなる指示も2つの学習ストリームに入る前に検証します。
結果
論文のアブストラクトでは、instruction followingベンチマークにおける「複数のモデルスケールとアーキテクチャにわたる改善」が報告されています。この設定ではIFEval、FollowBench、および類似の制約検証スイートが対象です。主要な主張は以下の通りです。
- クローズドループは、静的難易度のself-playが頭打ちになる地点を超えても改善を続けており、難易度進化メカニズムが固定データへの追加計算ではなく、有効な要素であることを示しています。
- 学習済みinstructorが生成しないheld-outの指示分布への汎化が確認されており、followerがinstructorの特異性を記憶するのではなく、汎用的な制約充足動作を学習していることが示唆されます。
- Filterをアブレーションすると、followerの性能とinstructorの安定性の両方が低下し、上記の失敗モードと一致しています。
- 難易度形状のinstructor報酬をアブレーション(すなわち、指示の新規性や長さを報酬とする)すると、静的難易度の動作が回帰し、頭打ちが再現されます。
提供された抜粋に完全な結果テーブルへのアクセスがないため、IFEval strict-prompt accuracyおよびFollowBench HSRの正確な差分はここでは再現しません。構造的な主張は、SEIFの改善曲線が研究された学習期間においてフラット化しないのに対し、ベースラインはフラット化するというものです。
限界とオープンクエスチョン
- 検証器のカバレッジ。 SEIFはプログラム的に充足可能性を確認できる指示にのみ有効です。オープンエンドな品質(有用性、事実性、スタイル)はループの外にあります。学習済み検証器への拡張は、SEIFが現在回避している報酬ハッキングのリスクを再導入します。
- Filterが単一障害点となること。 F に系統的な盲点がある場合、instructorはそれを利用します。論文では、学習後期に生成された敵対的指示に対するFilterのprecision/recallを定量化していません。
- Instructor側のmode collapse。 \phi 形状の報酬は目標成功率帯に到達するインセンティブを与えますが、これは狭い制約ファミリーによって達成できます。多様性正則化については言及されていますが、長期的な効果は不明確です。
- 共進化のダイナミクス。 収束や平衡に関する理論的分析はありません。交替スケジュール、グループサイズ K、KL係数 \beta はおそらく大きく影響し、チューニングコストは報告されていません。
- 能力のブリード。 制約followingへの強いRLは、推論や知識ベンチマークを低下させる可能性があります。SEIFがループ全体にわたって一般的な能力を保持するかどうかは、MMLU/GSM8Kスタイルのプローブによる測定が必要です。
なぜ重要か
SEIFは、安価な検証器が存在するドメインにおいて外部の監督なしに自己改善するためのクリーンなレシピを形式化しています。難易度形状のinstructor報酬と充足可能性フィルタを組み合わせることで、カリキュラムとポリシーが共進化します。これは「教師を使い果たした後にモデルは何を学習するのか」という問いに対する、より原則的な回答の1つであり、プログラム的なチェッカーが存在するコード、数学、ツール使用にも同じテンプレートが拡張できる可能性があります。
Source: https://arxiv.org/abs/2605.07465
Hacker News Signals
CUDA-oxide: NvidiaのRustからCUDAへの公式コンパイラ
CUDA-oxideは、Nvidia公式サポートプロジェクトであり、LLVMのNVPTXバックエンドを介してCUDAカーネルをRustで記述し、PTXにコンパイルすることを可能にします。このツールチェーンはrustcの既存のNVPTXターゲット(nvptx64-nvidia-cuda)に組み込まれ、CUDA固有のintrinsics、メモリ空間アノテーション、および同期プリミティブをRust crateとして上位に追加しています。カーネルコードは#![no_std]を使用し、スレッド・ブロックのインデックスビルトインを安全なラッパーとして公開します。このプロジェクトはproc-macroおよびリンカインフラストラクチャを提供し、CUDAドライバが標準のcuModuleLoadパスを経由してロードできる.ptxを生成します。
技術的な主要課題は、RustのTypeシステムとborrow checkerをCUDAのメモリ階層にマッピングすることです。アドレス空間(global、shared、local、constant)はRustの型レベルの区別を用いて異なるポインタ型としてエンコードされており、globalポインタが期待される箇所にsharedメモリポインタを渡すことはランタイムでの未定義動作ではなくコンパイル時エラーとなります。__syncthreads()のような生の同期プリミティブには依然としてunsafeブロックが必要ですが、ラッパーによって影響範囲が限定されています。
rust-gpu(SPIR-V/Vulkanをターゲットとする)やcudarc(RustのホストコードからCUDAを呼び出しつつカーネルはCで記述する)といったコミュニティプロジェクトと比較して、CUDA-oxideはカーネル側を直接ターゲットとし、リンクに公式CUDAツールチェーンを使用します。これは、SPIR-Vでは表現できないCUDA固有の機能(tensor core intrinsics、warpレベルプリミティブ)へのアクセスにおいて重要です。
制限事項も実在します。プロファイリング周辺のエコシステム(Nsight、ncu)は依然としてCUDA CソースコードまたはデバッグセクションつきのSASS/PTXを想定しており、Rustのcodegenはそれらをクリーンにemitできない場合があります。C ABIカーネルを期待する既存CUDAライブラリとのinteropには注意が必要です。このプロジェクトは初期段階であり、破壊的変更が見込まれています。
Source: https://nvlabs.github.io/cuda-oxide/index.html
Show HN: Needle: Gemini のツール呼び出しを 26M モデルに蒸留しました
Needle は、ツール呼び出しの検出と引数抽出に特化した 26M パラメータのモデルです。関数呼び出しトレースのキュレーション済みデータセット上で Gemini の挙動を蒸留することによって学習されています。主要な主張は、ユーザー発話をツール名と型付き JSON 引数にパースするという構造化されたサブタスクに対して、フロンティア LLM の完全な汎用性は不要であり、小さなモデルがその狭い分布において大型モデルと同等以上の性能を発揮できるというものです。
アーキテクチャは小型の encoder-decoder であると考えられます(リポジトリの詳細は乏しいですが、パラメータ数は hidden dim が狭い 4〜6 層の transformer と整合しています)。学習では、データパイプラインの段階に応じて、Gemini の出力をソフトターゲットとして、あるいは (tool, args) のラベル付きペアとして使用します。tokenizer とスキーマ条件付けのメカニズムが興味深い部分です。ツールスキーマ(JSON Schema 形式)が入力コンテキストの先頭に付加され、モデルはそのスキーマに制約された有効な JSON を出力するよう学習されます。
26M パラメータではモデルサイズが 100MB 未満に収まり、CPU 上で一桁台前半のミリ秒で推論が実行できます。これが実用上の動機です——1 回のユーザーターンで数十回のツールディスパッチ決定を行うエージェントシステムは、各決定に対してフル LLM のフォワードパスを行う余裕はありません。リポジトリのベンチマークでは、ホールドアウトされたツール呼び出しデータセットにおいて高い exact-match 精度が示されていますが、評価スイートは内部/キュレーション済みのものであり公開ベンチマークではないため、独立した検証が困難です。
未解決の問題として、未知スキーマへの頑健性(ゼロショット汎化)、複数のツールが適用可能な曖昧な発話の処理、そしてディスパッチ前に多段階の推論を要するツール呼び出しに対して蒸留シグナルが十分かどうかが挙げられます。スキーマ有効な JSON を出力する制約付きデコードのアプローチは標準化が進んでおり、任意の文法制約サンプラーに置き換えることが可能です。
Source: https://github.com/cactus-compute/needle
BunのRustによる実験的な書き直しがLinux x64 glibcでテスト互換性99.8%を達成
Jarred Sumnerは、BunのJavaScriptランタイム内部をRustで書き直す取り組みが、Linux x64 glibc上で既存のテストスイートの99.8%をパスすることを発表しました。BunはZig(JavaScriptCoreとの統合にはC++も一部使用)で書かれており、この書き直しはZigのコードベースをRustに置き換えつつ、JSエンジンとしてJavaScriptCoreを維持することを目標としています。
この99.8%という数値はBun独自のテストスイートに基づくものであり、Node.js互換性テストではないため、分母が重要です。BunはNode.jsのAPI互換性において歴史的にギャップがあり、この書き直しはそれらを直接解消するものではありません。この数値が示しているのは、Rustへの移植が現在のBunのセマンティクスに忠実であるということであり、より広範な互換性が向上したということではありません。
技術的には、この書き直しは大規模なZig-to-Rust移行に共通する課題に直面しています。Zigはborrowチェッカーを持たず、comptimeジェネリクスをRustのtraitシステムやlifetimeのルールに綺麗にマッピングできない形で使用しています。BunのZigコードはゼロコスト抽象化やインラインアセンブリのためにcomptimeを多用しており、Rustにおける相当する構造はproc macroや該当箇所ではconst fn、そしてそれ以外ではunsafeを必要とします。また、ZigのアロケータインターフェースはRustのGlobalAlloc/Allocatorトレイトとは異なります。
動機としては、おそらくエコシステムとコントリビューターへのアクセス性——RustはZigよりも大きなツールチェーンとコントリビューターベースを持つ——および長期的な保守性が考えられます。パフォーマンスへの影響は不明確です。ZigとRustはどちらもI/Oバウンドなランタイムにおいてほぼ同等のネイティブコードを生成でき、JSランタイムのボトルネックはほとんど常にJSエンジンであり、ホスト言語のバインディング層ではないためです。
Linux x64 glibcにおける0.2%の失敗率は、Windows、macOS、musl、およびARMターゲットの問題を未解決のままにしており、これらは歴史的に移植の摩擦が高い環境です。
Source: https://twitter.com/jarredsumner/status/2053047748191232310
SwiftでLLMをトレーニングする、第1部:行列積をGflop/sからTflop/sへ
この記事は、SwiftにおけるDense行列積の多段階最適化の記録であり、Metal経由でApple Siliconをターゲットにしています。単純な三重ループ実装(一桁台のGflop/s)から出発し、著者はキャッシュ局所性のためのタイリング、Swiftのsimd型によるSIMD intrinsics、そしてthreadgroup(共有)メモリを用いたMetal compute shaderという標準的な最適化階層を順に辿っていきます。
定量的な進展こそが本質です:素朴なSwiftはMシリーズハードウェアで約2 Gflop/sにとどまり、タイル化されたCPU実装では約50〜100 Gflop/sに達し、threadgroupメモリタイリングを用いたMetal shaderでは約1〜2 Tflop/sに到達します。これはFP32におけるAppleが公表するGPUピークスループットの目安に近い値です。タイリング戦略は、CUDAプログラマーが標準的な共有メモリGEMMで知っているものと同じです:出力行列をタイルに分割し、AとBのサブタイルをthreadgroupメモリにロードし、部分積を累積しながらK次元方向に反復します。threadgroupサイズとタイル寸法は、Mシリーズのメモリ帯域幅とレジスタファイルの制約に対してチューニングされています。
Swift固有の観察:Swiftの標準ライブラリにあるsimd_float4x4およびより幅広いSIMD型は、CPU上のNEON/AMX命令に直接マッピングされます。Metal Shading Language(MSL)は構文的にC++に近く、MTLComputePipelineStateを介したSwiftからの interopは直感的です。著者は、Accelerate/BLASが実運用における正しい答えであることを認めつつも、この演習はカスタムLLMトレーニングカーネルを理解するという教育的動機に基づいていると述べています。
認識されている制限事項:FP32のみ(LLMトレーニングにはBF16/FP16が重要)、初期カーネルにはバッチ次元がない、そしてMPS(Metal Performance Shaders)との比較ベースラインがない点が挙げられます。第1部はattentionやsoftmaxの前で明示的に終わります。
Source: https://www.cocoawithlove.com/blog/matrix-multiplications-swift.html
CERTがdnsmasqの深刻なセキュリティ脆弱性に対して6件のCVEを公開
CERT/CCは、dnsmasqに対する6件のCVEの協調開示を行いました。dnsmasqは、組み込みLinux、コンテナネットワーキング(DockerやKubernetesが使用)、家庭用ルーター、AndroidのホットスポットスタックにおいてあまねくAdしている軽量DNSフォワーダーおよびDHCPサーバーです。これらの脆弱性は、DNSキャッシュポイズニングとヒープ/スタックメモリ破壊のカテゴリにまたがっています。
最も深刻な問題はDNSレスポンスの解析部分にあります。dnsmasqのDNSSEC検証コードおよび特定のDNSレコードタイプの処理に、悪意のあるDNSレスポンスによって引き起こされ得るバッファ処理の誤りが含まれています。多くの環境においてdnsmasqは再帰リゾルバーとして動作するため、dnsmasqとアップストリームリゾルバーの間の経路上に位置できる攻撃者、またはアップストリームリゾルバーを制御できる攻撃者は、これらのバグを引き起こすレスポンスを細工することが可能です。キャッシュポイズニングのバリアント(Kaminskyスタイルのアタックサーフェスに基づく)は、正規のレスポンスとのレースを行う能力のみで成立し、経路の隣接性は必要ありません。
dnsmasqのコードベースはCで記述されており、シングルスレッドで動作し、ほとんどの環境において最小限のサンドボックス化でネットワーク入力を処理します。アタックサーフェスを考慮すると、メモリ破壊バグによるリモートコード実行は現実的ですが、実際の悪用可能性はビルドにおけるASLR/スタックカナリアの有無および各CVEの詳細に依存します。
実際の露出範囲は広範にわたります。ローカルリゾルバースタブとしてdnsmasqを使用するNetworkManagerを使用しているLinuxディストリビューション、すべてのDockerホスト(dnsmasqはデフォルトのブリッジネットワーク内で動作)、およびOpenWrtベースのルーターの膨大なインストールベースが対象となります。パッチはdnsmasq 2.91で提供されています。修正の提供から組み込みファームウェアへの展開までの遅延により、例によって長期にわたる脆弱なデバイスの残存が生じるでしょう。
オペレーターは、dnsmasq --version の出力でバージョンおよびDNSSECサポートがコンパイルされているか(リスクサーフェスがより高い)を確認する必要があります。
Source: https://lists.thekelleys.org.uk/pipermail/dnsmasq-discuss/2026q2/018471.html
Quack: DuckDBのクライアント・サーバープロトコル
DuckDBのブログに、クライアント・サーバー展開向けの新しいワイヤープロトコル「Quack」が紹介されています。DuckDBはアーキテクチャ上インプロセスデータベースですが、MotherDuck(マネージドサービス)やその他のマルチユーザー展開ではネットワークプロトコルが必要になります。設計目標は、バイナリ効率の高さ、DuckDBの列指向結果セットのサポート、および適切な場面でのArrow Flightトランスポートとの互換性です。
このプロトコルはデータのシリアライズにArrow IPCを基盤として構築されており、結果セットはArrow RecordBatchesとして送信されます。DuckDBの内部実行エンジンがネイティブにArrow互換の列指向バッファを生成するため、再エンコードのコストが排除されます。コントロールプレーン(クエリ送信、パラメータバインディング、トランザクションコマンド)は、TCP上の軽量なフレーミングレイヤーを使用しています。これは、行指向のバイナリまたはテキスト形式で行を送信し、行ごとのシリアライズオーバーヘッドが発生するPostgreSQLのワイヤープロトコルとは大きく異なります。
PostgreSQLワイヤー(DuckDBが互換性のために部分的にサポートしている)を再利用せずにカスタムプロトコルを採用した動機は、Postgresワイヤーがプロトコルレベルで行指向であり、列指向バッチを効率的に伝送できないためです。数百万行を返す分析クエリにおいて、列指向のArrow IPCはネットワーク上のバイト数を削減し、クライアント側でのマテリアライズコストを排除します。Arrow Flight RPC(gRPCベース)も代替手段ですが、gRPCの依存関係オーバーヘッドが加わります。Quackはより軽量なフレーミングを採用しているようです。
認証、TLS、マルチステートメントのトランザクションセマンティクスについても網羅されています。このプロトコルはOLTPワークロード向けのODBC/JDBCを置き換えることを目的としておらず、スキャン負荷が高く大きな結果セットを扱う分析ユースケースに最適化されています。
未解決の問題として、サードパーティのクライアントライブラリサポートが挙げられます。PostgreSQLワイヤープロトコルの普及により、あらゆる言語にクライアントが存在しますが、Quackは新たなドライバー開発が必要です。もっとも、Arrow Flightクライアントがこのギャップを部分的に埋めることができます。
Source: https://duckdb.org/2026/05/12/quack-remote-protocol
LakebaseアーキテクチャによるPostgresの高速書き込み
DatabricksはマネージドPostgresサービスであるLakebaseの背後にあるストレージアーキテクチャを解説しており、標準的なPostgresデプロイと比較して5倍の書き込みスループットを実現すると主張しています。アーキテクチャ上の重要な転換点は、WALをbuffer poolおよびストレージ層から分離(disaggregate)し、クラウドオブジェクトストレージと分散コンピュートに対応させた点にあります。
標準的なPostgresの書き込みパス:WALレコードはローカルディスク上のWALセグメントに書き込まれ、ダーティページはshared buffersに書き込まれ、最終的なチェックポイントがページをヒープファイルにフラッシュします。レイテンシは耐久性のためのWAL fsyncによって支配されます。LakebaseはローカルWALを分散ログサービスに置き換えています(AuroraのログStructuredストレージが行っていることに類似)。このサービスでは、WALレコードがレプリケートされたログ層に送信され、ページが書き込まれる前に確認応答が返されます。ログ層はWALをストレージに非同期で適用します。これにより、同期的なfsyncのレイテンシ(EBS/ローカルSSD上のミリ秒単位)が、低レイテンシなログサービスへのネットワーク往復(同一AZ内でサブミリ秒)に変換されます。
5倍という数値はWAL fsyncがコストの大半を占める書き込み負荷の高いOLTPベンチマーク(pgbench方式)によるものです。読み込みパフォーマンスは変わらないか、迂回処理によりわずかに悪化します。また、ログとページストアが分離されているため、このアーキテクチャは高速なブランチング(copy-on-writeクローン)を可能にし、これはdev/testワークフローに適しています。これはDatabricksがLLM fine-tuningのユースケース(トレーニング実行ごとにデータベースブランチを立ち上げる)として強調するセールスポイントです。
制限事項:このアーキテクチャは運用上の複雑さを増大させ、新たな障害ドメイン(ログサービス)を生じさせます。5倍という主張は標準的なシングルインスタンスPostgresとの比較によるものであり、Aurora、AlloyDB、Neonも同様のdisaggregated-WALのアイデアを採用しているため、バニラPostgresではなくこれらが適切な比較対象となります。
Source: https://www.databricks.com/blog/how-lakebase-architecture-delivers-5x-faster-postgres-writes
インシデントレポート: CVE-2024-YIKES
本記事は、自身のオープンソースプロジェクトにCVEが割り当てられたことを発見した開発者によるインシデントレポートです。ソフトウェア自体に脆弱性があったわけではなく、ダウンストリームのパッケージャーが既知の脆弱な依存関係をバンドルしたバージョンを配布していたことが原因でした。CVEはその依存関係ではなく、NVD上でプロジェクト名に対して登録されたため、プロジェクトをcritical severityスコアと結びつける恒久的な公開記録が生まれてしまいました。
技術的な核心はCVEエコシステムの仕組みにあります。NVDのエントリはCPE(Common Platform Enumeration)識別子をキーとしており、CPEのマッチングは粗いことが多く、特定のパッケージャーのmyappビルドに埋め込まれたlibfooに対するCVEが、脆弱性スキャナー上ではmyappの直接的な脆弱性として表示される場合があります。Dependabot、Trivy、Grypeなどの自動スキャナーはNVDフィードとCPEデータを解析しますが、「埋め込みコンポーネントに起因する脆弱性」と「本質的な脆弱性」を必ずしも区別しません。これにより、大規模なfalse positiveが発生します。
修正プロセスは官僚的で煩雑です。NVDエントリの修正にはMITREまたはCVEを発行したCNA(CVE Numbering Authority)との交渉、証拠の提出、そして遅い編集キューでの待機が必要です。GitHubのadvisoryデータベース、OSV.dev、NVDはこの期間中にデータが乖離している場合があり、一方を修正しても他方のスキャナー結果は修正されません。
本記事は構造的な問題を指摘しています。CVE/NVDシステムはベンダーの責任が明確な商用ソフトウェアを前提に設計されており、パッケージャー、フォーク、バンドラーにまたがって「影響を受ける製品」の識別子が曖昧になるオープンソースプロジェクトではその仕組みが破綻します。SCA(Software Composition Analysis)ツールを運用するセキュリティエンジニアにとって、これはalert fatigueの既知の原因であり、本インシデントレポートはそのノイズの発生源側における具体的なケーススタディを提供しています。
Source: https://nesbitt.io/2026/02/03/incident-report-cve-2024-yikes.html
注目の新規リポジトリ
NVlabs/cuda-oxide
標準のRustソースから直接PTXをターゲットとする、実験的なRust-to-CUDAコンパイラです。核となるアイデアは、Rust関数に#[kernel]属性を付与し、ツールチェーンがLLVMのNVPTXバックエンドを通じてそれらをloweringすることで、C++やCUDA Cの中間処理を完全に排除するというものです。“safe(ish)”という修飾語は重要です――通常のRustの所有権と借用の保証はRustレベルでは適用されますが、SIMT実行セマンティクス(warp divergence、shared memoryのレースコンディション)は型システムによって完全にモデル化されていないため、__syncthreadsやshared memoryアロケーションのようなintrinsicには依然としてunsafeブロックが必要です。
コンパイラパイプラインはrustcのcodegenレイヤーにフックし、nvptx64-nvidia-cudaをターゲットとするLLVM IRを出力し、標準のCUDAドライバAPIを通じてロード可能なPTXを生成します。カスタムDSLも、thrustやcublasのラッパーも不要――純粋なRustプリミティブのみです。これは、rust-cudaやaccelといったプロジェクトがこれまで必要としていたFFI境界を取り除くという点で重要です。
実用上の制限として、coreライブラリの全機能がPTXにクリーンにマップされるわけではなく(デバイスレベルではヒープアロケーションもpanicもできません)、テクスチャメモリやcooperative groupsのようなCUDA固有の機能には明示的なintrinsicの呼び出しが必要です。依然として実験的な段階にあり、NVLabsはこれをプロダクション向けツールチェーンではなく研究プロトタイプとして位置づけています。並列C++ビルドを管理することなく、Rustの型システムとツール群(cargo、clippy、rustfmt)を用いてカーネルコードを書きたい場合には検討する価値があります。
Source: https://github.com/NVlabs/cuda-oxide
rocky-data/rocky
Rustで書かれたSQL変換エンジンであり、dbtの代替として複数のアーキテクチャ上の追加機能を持つ位置づけです。主な特徴として、ブランチベースの開発(データパイプラインにおけるgitブランチに類似)、変換処理の決定論的な再現、およびRustの型システムを介したSQLモデルへのコンパイル時型安全性が挙げられます。カラムレベルの系譜(lineage)は実行時に推論されるのではなく、パース時に静的に追跡されるため、クエリを実行しなくても監査可能です。
このエンジンは単一の静的バイナリにコンパイルされ、Databricks、Snowflake、BigQuery、DuckDB向けのアダプタプラグインを備えています。モデルごとのコスト帰属は、依存関係DAGに対してウェアハウスの課金メタデータをタグ付けすることで計算され、アナリストはジョブ単位ではなく変換ノード単位でコスト内訳を把握できます。
技術的には、ブランチモデルはターゲットウェアハウス内の各ブランチに対して物理的または論理的な名前空間を別途維持し、増分DAG差分(incremental DAG diffing)によって変更されたノードのみをマテリアライズする仕組みです。コンパイル時の型安全性はRustのマクロシステムに依存しており、ウェアハウスへのラウンドトリップが発生する前に、宣言されたモデルコントラクトに対してSQLスキーマを検証します。
制限事項として、SQLダイアレクトのカバレッジはアダプタが公開する範囲に限定され、ブランチモデルはブランチ数に比例したウェアハウスストレージのオーバーヘッドを追加します。また、コンパイル時の保証はスキーマ宣言の正確さに依存するため、古い宣言や欠損した宣言があると保証が暗黙的に低下します。Apache 2.0ライセンスです。
Source: https://github.com/rocky-data/rocky
jeremiah-masters/dlht
DLHT(Deterministic Lock-free Hash Table)アルゴリズムを実装した、Go向けのlock-free並行ハッシュテーブルです。設計の核心は協調的リサイズにあります。一つのgoroutineがリサイズ操作を独占している間、他がブロックされるのではなく、並行してアクセスするすべての主体がバケットのマイグレーションにインクリメンタルに参加し、コストを各操作にわたって償却します。これにより、標準的なしきい値ベースのリサイズ設計に付きまとうレイテンシスパイクを回避しています。
キャッシュ効率はバケットパッキングによって実現されています。バケット内のエントリはキャッシュラインに収まるサイズの連続した配列に格納されるため、連結リスト設計と比べてポインタの追跡が減少します。ハッシュ関数とプローブシーケンスはgenericsを介してコンパイル時に固定されます。
ここでのlock-freedomとは、fast pathでのmutex取得が不要であることを意味します。進行保証は、厳密なwait-freeではなく、協調的マイグレーションプロトコルの下でのobstruction-freeです。ABAハザードの解消はhazard pointerまたはepochベースの再利用管理によって処理され(どちらのバリアントが有効かは実装を確認してください)、writerによってreaderがブロックされることはありません。
Go固有の課題として、GCがオブジェクトを移動する可能性があるため、lock-free構造を統合することは自明ではなく、unsafeとsync/atomicの慎重な使用が必要です。これが設計に暗示される「safe(ish)」という注意書きの主たる原因です。ベンチマークのターゲットは、sync.Mapの直列化がボトルネックとなる高並行性の読み取り多用ワークロードです。
Source: https://github.com/jeremiah-masters/dlht
Prompthon-IO/agent-systems-handbook
本番環境のLLMエージェントシステムのエンジニアリング面を体系的にまとめたリファレンスです。エージェントループのアーキテクチャ、plan-execute・ReAct・reflectionといったエージェント型ワークフローパターン、LangGraphベースのオーケストレーション、そしてMCP(Model Context Protocol)とA2A(Agent-to-Agent)通信規格を網羅しています。各ステップでcontext windowに何を入れるかを管理する「context engineering」についても独立した章が設けられており、エージェント関連のチュートリアルでは往々にして軽視されがちなテーマに踏み込んでいます。
エージェントメモリの分類(in-context・外部ベクトル・key-value・エピソード記憶)、非決定論的なエージェント軌跡に対する評価手法、オブザーバビリティの計装(ツールコールのトレース、ステップ成功率の計測、タスク当たりコスト)についても取り上げています。マルチエージェントアーキテクチャのセクションでは、コーディネーター・ワーカーパターン、共有状態管理、障害の分離について論じています。
verifiable RAGと新興のエージェントランタイムに関するセクションは、2025年時点のフィールドの現状を反映しており、根拠検証を伴う検索パイプラインや、実行サンドボックス・ツールレジストリといったランタイム環境を扱っています。実践的な志向が際立っており、サーベイ論文というよりも意見の明確なエンジニアリングガイドであり、文献レビューよりもrunbookに近い性格を持っています。
エージェントフレームワークをブラックボックスとして使うのではなく、エージェントインフラを構築するエンジニアの体系的なオンボーディング資料として有用です。
Source: https://github.com/Prompthon-IO/agent-systems-handbook
getagentseal/codeburn
AIコーディングアシスタント(現在はClaude Code、OpenAI Codex、Cursor)のトークン消費量とコスト配分を追跡するためのターミナルUIダッシュボード(TUI)です。核となる価値提案はオブザーバビリティ(可観測性)であり、トークン使用量をセッション単位・ファイル単位・オペレーション単位で分解し、ターミナル上でインタラクティブに表示します。
技術的には、codeburnは各ツールが出力するローカルのログファイルと使用状況テレメトリを解析し、各プロバイダーの現行料金を用いたコストモデルに集約した上で、TUIフレームワーク(Rustエコシステムの潮流を踏まえるとratatuiや類似のものと思われます)を通じて結果をレンダリングします。インタラクティブなインターフェースにより、時間ウィンドウ・プロジェクト・オペレーション種別ごとにドリルダウンが可能です。
解決しようとしている問題は現実のものです。特にClaude Codeは、単一のエージェントセッションで数百万トークンを消費することがあり、プロバイダーのダッシュボードはかなりの遅延を伴う粗い粒度のサマリーしか提供しません。ローカルかつリアルタイムのビューを持つことで、開発中のフィードバックループが閉じられます。
注記すべき制限事項として、コストモデルは現行の料金体系にハードコードされており、プロバイダーの価格改定に伴いずれが生じることが挙げられます。また、ログフォーマットの解析はツールのバージョンアップに対して脆弱であり、「オブザーバビリティ」は予測的ではなく遡及的なものです(予算の強制適用やレート制限機能はありません)。それでも、リリース直後に6,000以上のスターを獲得したことから、需要シグナルは明確です。エージェント型コーディングにおけるコスト透明性は、未だ満たされていないニーズです。
Source: https://github.com/getagentseal/codeburn
earthtojake/text-to-cad
LLMベースのコーディングエージェントを通じて3Dモデル生成を駆動するための、CADスキルとテストハーネスのコレクションです。本プロジェクトが対象とするワークフローは、コーディングエージェント(例:Claude、GPT-4o)がOpenSCAD、CadQuery、または類似の環境でパラメトリックなCADスクリプトを記述し、それを実行してジオメトリを生成するというものであり、メッシュデータを直接生成するアプローチとは異なります。
「スキル」とは、構造化されたpromptテンプレートとツール定義であり、特定のCADスクリプティング環境のイディオム(寸法のパラメータ化の方法、ブール演算の構築方法、座標系の扱い方、エクスポート可能なジオメトリの生成方法など)をエージェントに教えるものです。ハーネスは自動評価を提供します:テキスト記述と参照モデルが与えられた場合に、エージェントの出力とのジオメトリ的類似度を測定します。
これは見た目よりも難しい問題です。CADスクリプトは命令的であり、パラメータの順序に敏感です。エージェントは構文的には有効でもジオメトリ的には縮退した出力(体積ゼロのソリッド、非多様体メッシュ)を頻繁に生成します。ハーネスはこの問題に対処するために、生成されたスクリプトをサンドボックス化された実行環境で動作させ、スコアリング前にメッシュ検証チェックを適用します。
オープンソースという枠組みにより、チームは好みのLLMバックボーンを差し替えたり、ドメイン固有のジオメトリ(機械部品、建築要素)向けにスキルライブラリを拡張したりすることができます。2,400以上のスターは、使いやすい評価インフラを待ち望んでいた生成CADコミュニティにおける支持を示しています。
Source: https://github.com/earthtojake/text-to-cad
Zafer-Liu/Data-Analysis-Agent
SQLやPythonに深い知識を持たないビジネスアナリストを対象とした、LLMを活用したデータ分析エージェントです。アーキテクチャは標準的なtool-useループに従っており、自然言語クエリをLLMが解析し、データの取得と変換のステップの列へと分解し、接続されたデータソースに対して実行した後、サポートする可視化とともに結果を自然言語で要約します。
技術スタックはReActスタイルのエージェントループを使用しており、SQLの実行、dataframeの操作(おそらくpandas)、およびグラフ生成のためのツール定義が含まれています。エージェントは会話状態を維持することで反復的な改善をサポートしており、例えば最初の集計クエリの後に「今度はリージョンXでフィルタリングして」といった操作が可能です。
ビジネスアナリストを対象としたオーディエンスにとって重要な設計上の選択肢は以下の通りです:(1) SQL生成において曖昧なスキーマ名を適切に処理できること、(2) 生成されたSQLが失敗した場合のエラー回復が自動的に行われること、(3) ユーザーの設定なしに可視化がレンダリングされること。この実装がこれら3点をすべて堅牢に処理できるかどうかは、リポジトリの説明だけでは不明です。
中国語のドキュメントが主要なターゲット市場を示しており、これはLLMのバックエンド選択に影響する可能性があります(OpenAIに加えて、中国語性能に優れたQwenや類似モデルが含まれる可能性が高いです)。1.1kのスターを持ち、エージェント駆動のBIツールのリファレンス実装として注目を集めています。
Source: https://github.com/Zafer-Liu/Data-Analysis-Agent
lightseekorg/tokenspeed
「光速」を自称するLLM推論エンジンで、トークン生成における最大スループットおよび最小レイテンシを目標としています。名称とキャッチフレーズは積極的な最適化へのこだわりを示唆していますが、リポジトリはまだ初期段階であり、その野心に比べてテクニカルドキュメントが乏しい状況です。
利用可能なコードと構造から判断すると、このエンジンはcontinuous batching(固定シーケンス長へのパディングではなく、decodeステップでリクエストを動的にバッチ処理する手法)、フラグメンテーションを回避するためのページングまたはチャンク割り当てによるKV cacheの管理、そしておそらくattentionおよびfeed-forwardレイヤーに対するCUDA kernel fusionを実装しているようです。これらはvLLMやTensorRT-LLMといったプロダクション向け推論エンジンにおける標準的な技術です。
差別化の主張が成立するとすれば、vLLMが提供する範囲を超えたkernel レベルの最適化が必要になります。具体的には、特定のハードウェアターゲット向けのカスタムCUDA kernel、より積極的なspeculative decoding、あるいは異なるメモリ管理戦略などが考えられます。スター数973でドキュメントが限られている現状では、パフォーマンスに関する主張を独立して検証することは困難です。
このプロジェクトを注目すべき理由:推論スループットは依然として活発な研究・エンジニアリング上の課題であり、リファレンス実装(HuggingFace Transformers)と最適化済みエンジン(TensorRT-LLM)との間には依然として大きな差が存在します。特定のハードウェアやモデルサイズのニッチを開拓する新規参入者は、真の価値を提供できる可能性があります。採用を決める前にベンチマークで評価することを推奨します。