Daily AI Digest — 2026-05-12
arXiv Highlights
Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs
Problem and motivation
After frontier LLMs reached IMO gold-medal performance, olympiad-style benchmarks have lost discriminative power at the top. Research-level mathematics is the natural next target: it requires the same step-by-step reasoning but applied to problems closer to open mathematical knowledge. Existing research-level benchmarks are tiny — Riemann-Bench has 25 problems, FrontierMath-Tier 4 has 50 — which makes statistical separation of frontier systems unreliable. Soohak (SH^2, from 수학 시험, “math exam”) is a 439-problem benchmark authored from scratch by 64 mathematicians, plus a larger Mini split, designed to provide both scale and difficulty.
Construction
The full contributor pool reached 105 accepted-question authors across 31 organizations: 48% faculty, 23% graduate students/postdocs, 25% undergraduates, 5% undisclosed. 72 of 86 primary-system contributors were recruited via direct outreach to math departments. Compensation was per-accepted-question, with a $260{,}000 pool and per-question payments ranging from $36 to $3{,}623 (capped at $20{,}000 per contributor). All submissions were text-only LaTeX, in English or Korean, with a complete solution and an explicit final-answer line. Contributors signed an originality clause forbidding AI assistance, plus an NDA and IP-transfer agreement.
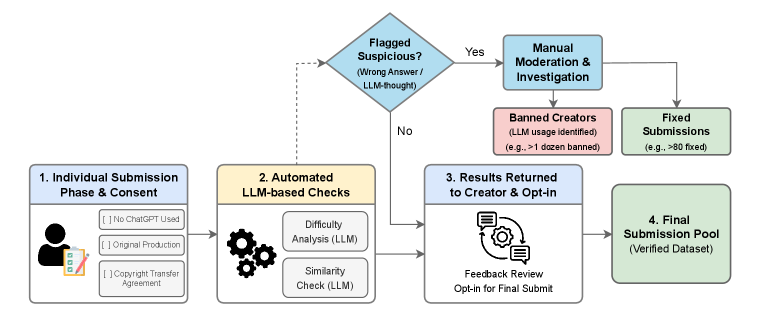
The pipeline is a multi-gate filter: originality/copyright agreement, automated screening with model-gated routing and similarity checks, two human reviewers, contributor-controlled opt-in, then final inclusion. Submissions found to be AI-generated removed the contributor entirely (“banned creators”). The model-gated routing is operationally important: items that several frontier models solve cleanly are routed into Mini; items that survive the model gate populate Challenge.
The benchmark splits into: - SOOHAK-Mini (n=702): merges the first two internal model gates; olympiad to early graduate level. - SOOHAK Challenge (n=340): hard, research-flavored items. - SOOHAK Refusal (n=99): a separate split probing recognition of ill-posed problems — a capability intrinsic to research mathematics, where the first task on a fresh question is often deciding whether it is well-posed at all.
Evaluation protocol
Eleven models were evaluated with reasoning enabled: Gemini-3-Pro/Flash, GPT-5/-Mini (Medium reasoning), Claude-Opus-4.5/Sonnet-4.5, Grok-4.1-Fast (closed); Qwen3-235B-A22B-thinking-2507, GPT-OSS-120B, Kimi-2.5, GLM-5 (open-weight). Reported metrics are Avg@3 and Pass@3, scored purely on final-answer correctness with no partial credit.
Main results
On Mini, frontier models cluster: GPT-5 leads Avg@3 at 72.22, Gemini-3-Pro at 71.70, Grok-4.1-Fast at 70.66. Difficulty separation appears on Challenge:
| Model | Challenge Avg@3 | Pass@3 |
|---|---|---|
| Gemini-3-Pro | 30.39 | 44.12 |
| GPT-5 | 26.37 | 40.88 |
| Grok-4.1-Fast | 18.43 | 30.88 |
| GPT-5-Mini | 18.82 | 28.82 |
| Gemini-3-Flash | 15.69 | 25.59 |
| Kimi-2.5 | 13.87 | 20.00 |
| GPT-OSS-120B | 11.27 | 18.53 |
| Claude-Opus-4.5 | 10.39 | 18.82 |
| GLM-5 | 9.61 | 18.24 |
| Qwen3-235B | 8.04 | 15.00 |
| Claude-Sonnet-4.5 | 5.69 | 10.29 |
All open-weight models stay below 15% Avg@3. 124 Challenge items are unsolved by any evaluated model, and 170 items are unsolved or missed across the family — already exceeding the entire size of Riemann-Bench’s unsolved set (\geq 23/25).
Refusal yields a different ordering. GLM-5 leads at 49.49 Avg@3 / 73.74 Pass@3, GPT-OSS-120B at 43.77/60.61, GPT-5 at 43.09/61.62. Qwen3-235B collapses to 2.69 Avg@3 — it almost never identifies ill-posed problems, suggesting an answer-emission prior that overrides well-posedness checking. The decoupling between Challenge rank and Refusal rank indicates that solving and recognizing-unsolvability are distinct skills not jointly optimized in current post-training.
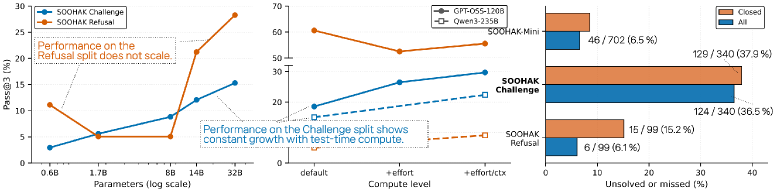
The compute-scaling panel shows Pass@3 climbing with parameter count across Qwen3 0.6B–32B on both Challenge and Refusal, and test-time scaling for GPT-OSS-120B (medium 16k tokens; hard 16k; hard 81{,}920) yielding monotonic gains, indicating Soohak is not yet saturated by either dimension.
Human baselines
Five teams of five solvers each (CS-major IMO experience; Math-major IMO experience; Math-major IMO Gold; Math major; Math researchers) attempted a 79-problem subset (49 Calibration, 30 Challenge upsampled) under a 4.5-hour budget, allowed CAS, programming, and non-AI search. Models received Pass@1 on the same 79 items.
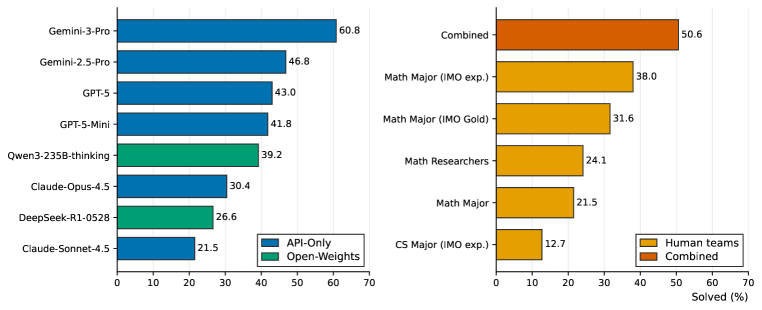
Only Gemini-3-Pro exceeds combined-human coverage at 50.6%. The strongest single team is the Math Major (IMO experience) team. Math researchers (Team E) do not dominate over IMO-trained undergraduates on this set, consistent with the benchmark’s mix of olympiad-flavored and research-flavored items.
Limitations and open questions
- Sessions were not standardized across human teams, adding variance at frontier difficulty.
- Pure outcome-based scoring with text-only LaTeX excludes problems requiring diagrams or genuinely open conjectures, so “research-level” here means hard problems with a verifiable final answer rather than open mathematics proper.
- The Challenge gate was deliberately not pushed harder against top closed systems; this preserves scale at the cost of some headroom for Gemini-3-Pro and GPT-5.
- Refusal performance does not correlate with Challenge solving, but the benchmark does not yet disentangle calibration training from genuine ill-posedness detection.
Why this matters
Soohak provides the first research-flavored math benchmark with enough items (439 graded, plus 702 in Mini) to statistically separate frontier systems, and it exposes a sharp gap — 30% Avg@3 for the best model — that olympiad benchmarks no longer reveal. The Refusal split formalizes a research skill prior benchmarks ignored, and the rank inversion between solving and refusal signals an underexplored axis for post-training.
Source: https://arxiv.org/abs/2605.09063
Geometry Conflict: Explaining and Controlling Forgetting in LLM Continual Post-Training
Problem
Continual post-training of LLMs sequentially injects new domains, skills, or behaviors via updates \Delta_t = \theta_t - \theta_{\text{pre}}. Existing tools — sequential SFT, EWC, replay (FOREVER), task-arithmetic merging (TIES, DARE, AIMMerging) — patch forgetting but offer no principled criterion for when a new update will transfer cleanly versus when it will overwrite previously acquired capabilities. Practical decisions (which updates to merge, with what weighting, at which layers) are made by trial and error. This paper argues that forgetting is governed by a measurable geometric property of the updates relative to the evolving model state, and turns that diagnostic into a data-free merging algorithm (GCWM).
What governs forgetting
The authors represent each task update by its layer-wise covariance C_i^{(\ell)} = (\Delta_i^{(\ell)})^\top \Delta_i^{(\ell)} + \lambda I and contrast four candidate predictors of retention loss across Qwen3 (0.6B–14B) under Seq. SFT, EWC, FOREVER, and AIMMerging: update norm, subspace alignment ratio (SAR), gradient conflict, and Bures–Wasserstein “geometry conflict” measured both pairwise among active updates and against the current model state.
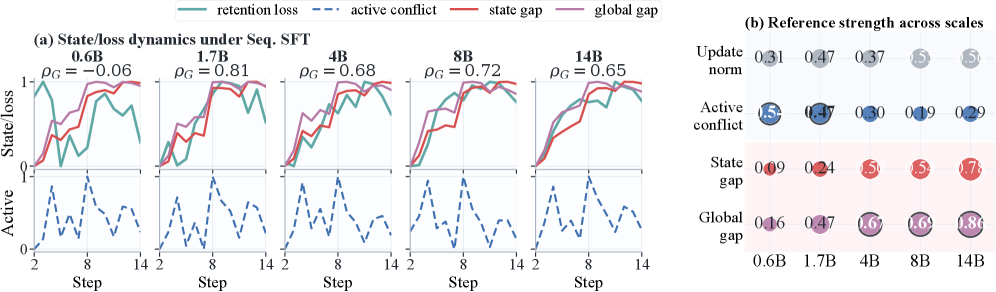
The empirical finding is that update norm gives only a coarse signal (|\rho_s|=0.48 Spearman with retention loss), pairwise active conflict is weaker still (|\rho_s|=0.30), but the state-relative gap — geometry mismatch between the new active updates and the geometry of the accumulated model state — reaches |\rho_s|=0.59 globally and grows monotonically with scale, from 0.16 at 0.6B to 0.86 at 14B. In other words, forgetting is not “how far the parameters move” but “how incompatible the move is with the geometry already encoded by previous updates.”
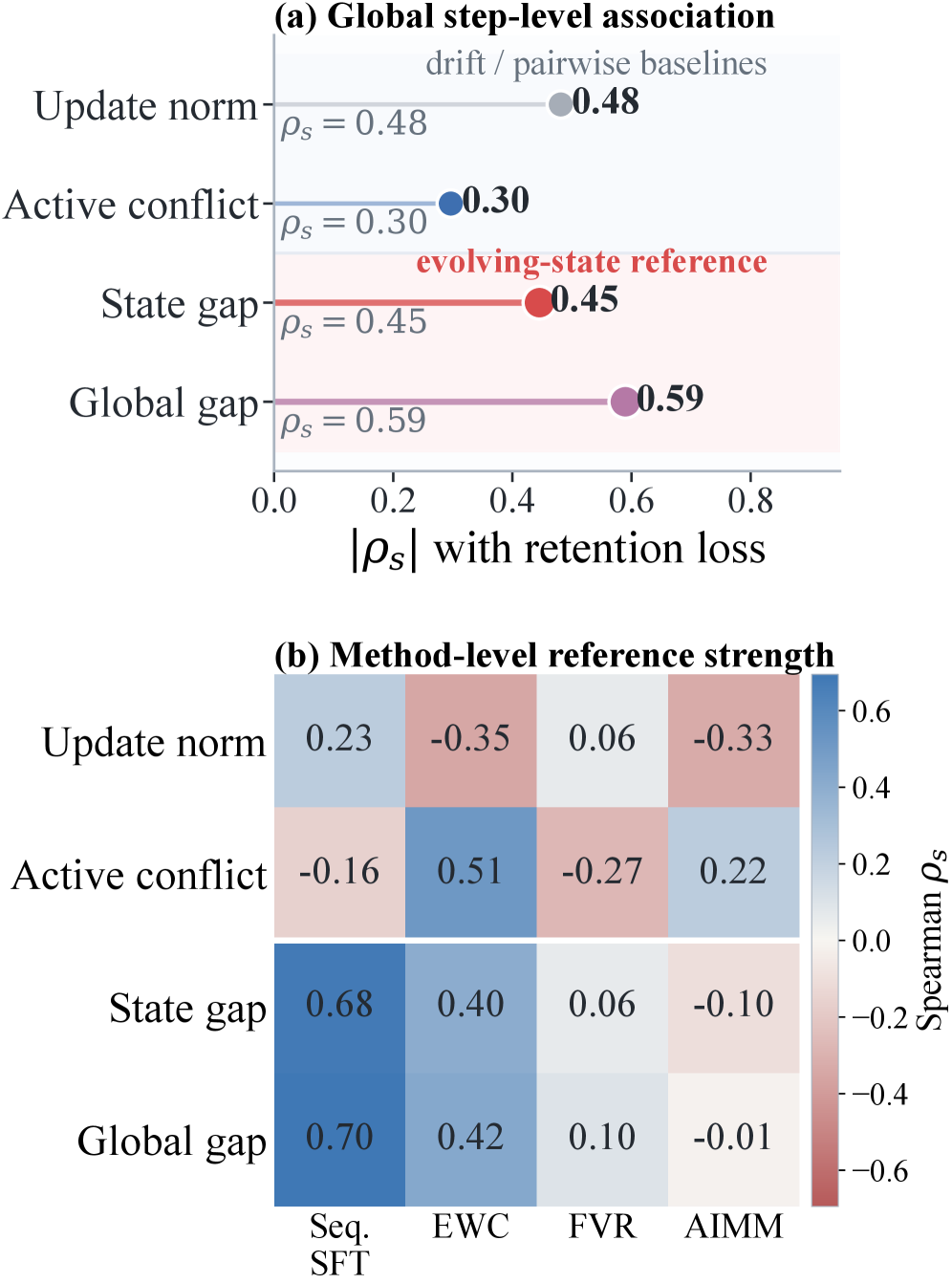
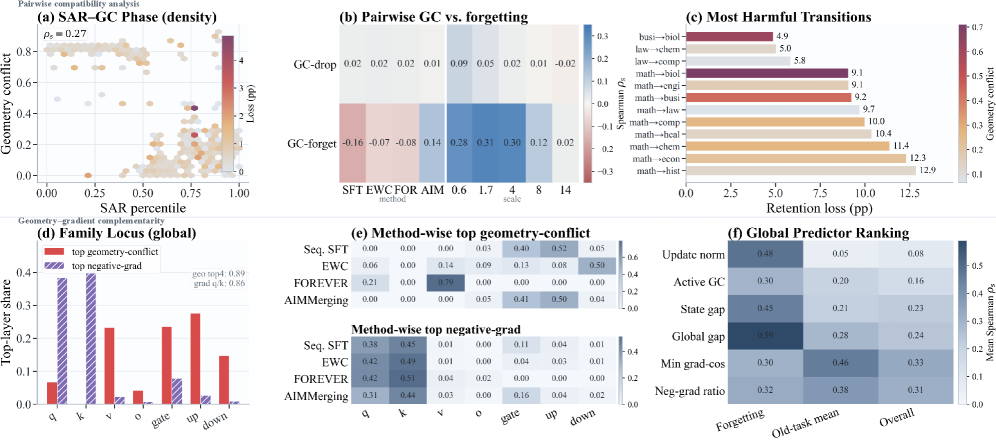
A complementary stratification (Fig. 3) shows that SAR and geometry conflict together carve task pairs into distinct transfer regimes (positive transfer, neutral, interference), while gradient conflict captures a different failure mode concentrated in top-layer parameter shares. Geometry and gradient conflict are therefore complementary rather than redundant.
GCWM: turning the diagnostic into a controller
GCWM is a data-free merging procedure parameterized purely by the active task vectors. For each linear layer \ell it:
- Computes truncated SVDs \Delta_i^{(\ell)} \approx U_i \Sigma_i V_i^\top and forms a shared right-singular basis Q^{(\ell)} = \mathrm{orth}([V_1^{(\ell)},\dots,V_m^{(\ell)}]).
- Projects each update covariance into the shared basis: B_i^{(\ell)} = (Q^{(\ell)})^\top C_i^{(\ell)} Q^{(\ell)}.
- Measures pairwise normalized Bures–Wasserstein conflict \gamma_{ij}^{(\ell)} = \frac{d_B^2(B_i^{(\ell)}, B_j^{(\ell)})}{\mathrm{tr}(B_i^{(\ell)}) + \mathrm{tr}(B_j^{(\ell)}) + \varepsilon},\quad d_B^2(A,B)=\mathrm{tr}(A)+\mathrm{tr}(B)-2\,\mathrm{tr}((A^{1/2}BA^{1/2})^{1/2}).
- Aggregates to a layer score g^{(\ell)} = \sum_{i<j} w_{ij}\gamma_{ij}^{(\ell)} and converts to a sigmoidal gate \alpha^{(\ell)} = \alpha_{\min} + (\alpha_{\max}-\alpha_{\min})\,\sigma(\kappa(g^{(\ell)} - \tau)).
At step t, only the incremental portion of the merged update modulated by \alpha^{(\ell)} is applied: high-conflict layers receive stronger geometry-aware correction (effectively shrinking the merge into compatible directions), low-conflict layers pass through. Construction is closed-form, requires no replay data, no held-out evaluation, and no gradient access — only the task vectors.
Results
On Qwen3 backbones the domain-continual MMLU-Pro (14 sub-domains, 1k samples each) shows GCWM closing most of the gap to multi-task joint training:
- 1.7B: MTL upper bound 44.4 → Seq. SFT 36.8, EWC 40.0, AIMMerging 41.8, OPCM 41.7, GCWM 43.5.
- 8B: MTL 65.3 → Seq. SFT 55.2, AIMMerging 62.9, OPCM 61.9, GCWM 63.7.
- 14B: MTL 68.6 → Seq. SFT 60.4, AIMMerging 66.4, OPCM 66.6, GCWM 67.8.
GCWM is the best non-MTL method in every block, with the largest improvement over Seq. SFT at 8B (+8.5 points) and over the strongest data-free baseline (OPCM/AIMMerging) of 0.8–1.8 points across scales. Per-domain, GCWM is competitive on traditionally interference-prone categories (CS at 8B: 64.7 vs. 62.8 OPCM; Hist at 14B: matches OPCM at high accuracy) suggesting the gate is doing useful per-layer modulation rather than uniform shrinkage.
Limitations and open questions
The covariance C_i^{(\ell)} = (\Delta^{(\ell)})^\top \Delta^{(\ell)} is a coarse proxy for task-induced geometry — a true Fisher would require data. The truncated-SVD shared basis and the threshold \tau, sharpness \kappa, and rank m are hyperparameters whose sensitivity is not quantified in the main text. The state-relative analysis is correlational, with |\rho_s| up to 0.86 but not a causal mechanism; the gap to MTL still ranges 0.8–1.6 points, leaving headroom that pure update-geometry cannot close. Capability-continual results (math vs. code) are referenced but not shown above. Whether geometry conflict generalizes to RL post-training, where update geometry is noisier and policy-state coupled, remains open.
Why this matters
Most current continual post-training work treats forgetting as an inevitable cost to be amortized via replay or regularization. This paper reframes it as a measurable geometric incompatibility between an incoming update and the evolving model state, and shows the same quantity acts as an effective per-layer gating signal — recovering most of the joint-training accuracy without data, gradients, or replay. That makes update integration a controllable, predictable operation rather than an empirical lottery.
Source: https://arxiv.org/abs/2605.09608
Model Merging Scaling Laws in Large Language Models
Problem
Model merging — averaging or task-arithmetic combinations of fine-tuned checkpoints — is a cheap alternative to multitask SFT, but practitioners have no quantitative rule for the returns of adding more experts or scaling the base model. Should you merge a 9th expert or train a larger backbone? When does the marginal gain fall below noise? This paper provides an empirical scaling law for the cross-entropy of merged LLMs as a joint function of base size N and expert count k, validates it across four merge rules and seven backbone sizes, and derives a small theoretical model that explains the 1/k tail.
Setup and law
For each backbone N \in \{0.5, 1.5, 3, 7, 14, 32, 72\} B (Qwen-2.5 family, 10,866 checkpoints total) the authors train M=9 domain-specialist experts spanning algebra, analysis, geometry, discrete math, number theory, code, chemistry, physics, biology. For a merge rule (Average, TA, TIES, DARE) and target subset size k \in \{1,\ldots,9\}, they evaluate either all \binom{M}{k} subsets or a uniform sample, then form the empirical conditional expectation
\widehat{\mathbb{E}}[L\mid N,k] = \frac{1}{S_{N,k}} \sum_{s=1}^{S_{N,k}} L(N,k,s).
Per-subset losses are noisy (visible bands in the scatter), but the per-k mean is a smooth monotone curve with diminishing returns.

The central empirical claim is that this expectation fits a floor-plus-tail law,
\mathbb{E}[L\mid N,k] = L_\infty(N) + \frac{A(N)}{k+b},\qquad b \ge 0\ \text{small}.
L_\infty(N) is the asymptote as more experts are merged (interpreted as the best the merge rule can recover at that backbone size) and A(N)/(k+b) is the merging tail. Both holds in-domain (eval on the donor’s own domain) and cross-domain (macro-average across all nine). The law accommodates Average, TA, TIES, and DARE with the same functional form; only the coefficients change.
Two regularities follow directly: (i) most gains arrive early, since 1/(k+b) drops sharply for small k, and (ii) subset-level variance shrinks as k grows, because averaging over more donors concentrates the random-subset distribution around its mean. Panel 5 of Figure 3 makes this contraction explicit on algebra.
Theoretical sketch
The authors’ theory casts merged parameters as a uniform average of k task vectors with bounded pairwise interference. Under mild regularity of the loss around the base model, a second-order expansion gives an excess loss term whose expectation over uniform k-subsets scales as 1/k, reproducing the A(N)/(k+b) tail with b absorbing finite-k corrections. L_\infty(N) is then identified with base-model curvature plus residual cross-domain mismatch — properties that are intrinsic to the backbone and the donor pool, not to k.
Quantitative behavior and pool-size analysis
Floors L_\infty(N) track tight power laws in N and are essentially invariant to whether the donor pool has M=8 or M=7 available domains. The pool-size effect is concentrated in the tail A(N): moving from M=8 to M=7 makes A(N) flat-to-decreasing in N on chemistry/physics, while math-like domains barely move. The interpretation is that a more diverse pool supplies complementary donors that suppress residual cross-domain mismatch in the A(N)/(k+b) term — most visible at moderate-to-large k and larger N. The floor is set by the backbone; the tail is set by donor diversity.
The fitted law also gives the planning levers the authors advertise: invert it to estimate the k needed to hit a target loss, detect a stopping point where A(N)/(k+b) falls below a tolerance, and compare scaling N versus adding experts under a fixed compute budget. Because expert post-training itself follows a separate scaling pattern in N and post-training compute (Figure 11 in the paper), the merging law composes cleanly with expert-side scaling for end-to-end budgeting.
Limitations and open questions
- The grid is single-family (Qwen-2.5) and single-task-flavor (math/science/code domains); the floor-power-law in N may not generalize to mixed-modality or instruction-following losses where evaluation is not pure CE.
- M=9 is small; the 1/(k+b) form is verified only up to k=9, and the asymptote L_\infty(N) is an extrapolation rather than a measurement.
- The theory assumes bounded pairwise interference between task vectors; pathological merge rules or strongly conflicting experts (e.g., adversarial fine-tunes) would violate this.
- Subset-level variance is acknowledged but not modeled — the law predicts means, so for risk-sensitive deployment one still needs a separate variance estimator.
- No analysis of whether the same law holds for downstream metrics (accuracy, pass@1) rather than CE.
Why this matters
A predictive, two-parameter law for merging turns “try a few combinations” into a planning problem: given a base size and a donor pool, you can estimate the loss reachable with k experts before training any of them, and decide whether marginal compute is better spent enlarging N or adding donors. This makes merging a quantitatively comparable alternative to multitask SFT rather than a heuristic shortcut.
Source: https://arxiv.org/abs/2509.24244
G-Zero: Self-Play for Open-Ended Generation from Zero Data
Problem
Self-evolving LLM pipelines like R-Zero rely on majority voting or rule-based verifiers, which only function in closed, verifiable domains (math, code with unit tests). Extending self-play to open-ended generation typically falls back on an LLM-as-a-judge, whose scalar scores are upper-bounded by the judge’s own capability and are notoriously susceptible to reward hacking (length bias, sycophancy, stylistic exploits). G-Zero proposes an alternative supervision signal that is generated entirely from the trainee model’s own internal distribution, removing both external verifiers and judges from the loop.
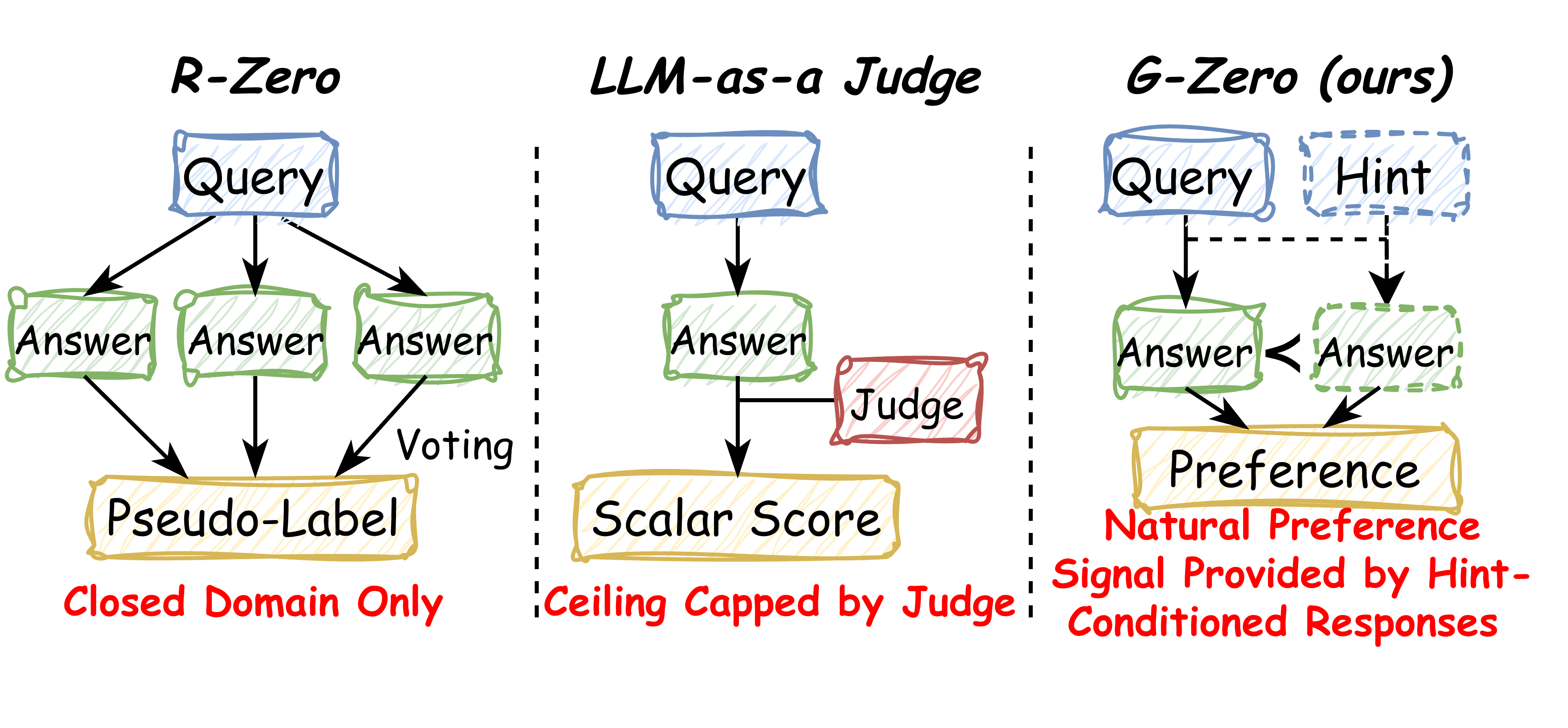
Method
G-Zero is a two-player co-evolutionary loop between a Proposer \pi_P and a Generator \pi_G, glued together by a single intrinsic scalar called Hint-\delta.
Hint-\delta. For a query q, a Proposer-generated hint h, and the Generator’s unassisted response a_{\text{hard}} \sim \pi_G(\cdot \mid q) with tokens (a_1,\dots,a_T),
\delta(q,h,a_{\text{hard}}) = \frac{1}{T}\sum_{t=1}^{T}\Big[\log\pi_G(a_t\mid q, a_{<t}) - \log\pi_G(a_t \mid q, h, a_{<t})\Big].
This is the per-token mean log-likelihood drop induced on \pi_G’s own unassisted trajectory when h is prepended. Per-token (rather than sequence-sum) normalization is the critical design choice: on a 1,824-sample R1 pool the Spearman correlation between \delta and |a_{\text{hard}}| is -0.41, i.e., the obvious length-exploit channel is closed off. A large \delta requires both that a_{\text{hard}} was uncertain/flawed (hard query) and that h contains information that genuinely reorganizes \pi_G’s next-token distribution (informative hint).
Proposer phase. With \pi_G frozen, \pi_P samples (q_i, h_i) pairs and is updated via GRPO using \delta as the reward. This drives the Proposer toward the Generator’s blind spots — regions where \pi_G is wrong but recoverable given a small amount of guidance.
Generator phase. With \pi_P frozen, the Generator answers each q_i both with and without h_i. A \delta-percentile filter selects pairs into the round-R preference dataset \mathcal{D}_{R+1}, where a (with hint) is the chosen response and a_{\text{hard}} is the rejected one. \pi_G is then updated with DPO. The hint is dropped at inference: the Generator must internalize the structural improvement, not depend on h.
The authors prove a best-iterate suboptimality bound for an idealized standard-DPO variant under two conditions: (i) the Proposer induces sufficient coverage over the query-hint space, and (ii) the \delta-filter keeps pseudo-label noise low. Both assumptions are non-trivial in practice but make the role of the filter explicit — it is not just data hygiene but a precondition for convergence.
Results
Experiments use Qwen3-8B-Base and Llama-3.1-8B-Instruct, deliberately spanning a base model and an aligned instruction model from different families.
The most informative analysis concerns what kind of data the loop selects. After \delta-filtering on Qwen3-8B-Base (Round 1), only 9.6% of the DPO pool is math and 9.0% is code; the bulk is advice (30.2%), other (24.1%), writing (17.4%), and explanation (9.6%). The mean \delta values are highest in writing (0.060) and explain (0.058) — not in math (0.045). Yet, under the [0,50] percentile filter (the G-Zero default), the model improves on Math from 8.81 to 11.78 (absolute), Chat from 8.94 to 9.07, IFEval from 52.78 to 53.03, and average from 33.95 to 34.96. Reasoning gains arise from structural transfer of compositional patterns elicited in non-verifiable categories, not from in-domain math memorization.
Filter ablations show the design is non-trivial: [0,50] yields avg 34.96, [20,80] yields 34.40, [50,100] yields 34.04, and the unfiltered [0,100] yields 34.65. The high-\delta tail alone is worse than the low/mid range — consistent with the theory that extreme \delta values are noisy pseudo-labels (hints that overwrite rather than refine).
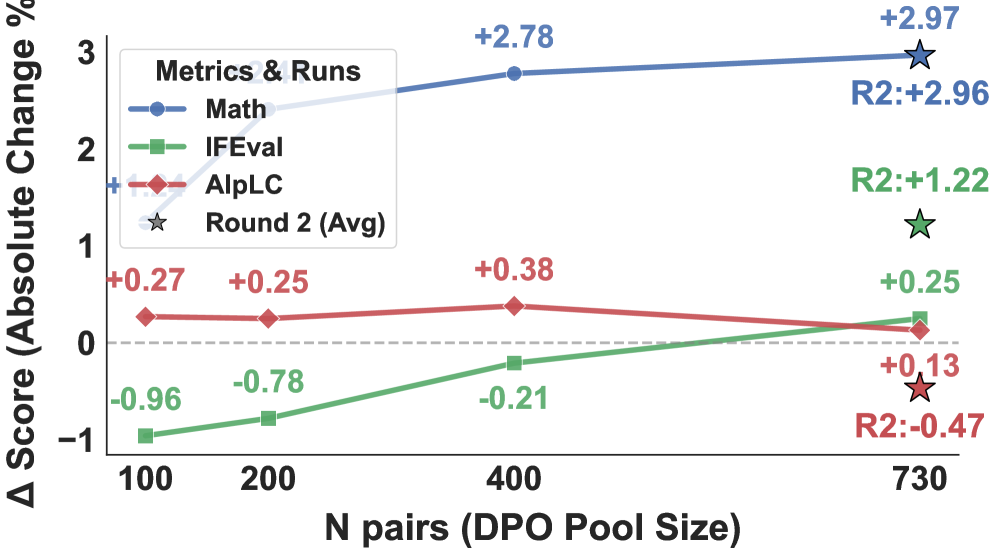
Figure 3 shows incremental scaling of the DPO pool (N \in \{100, 200, 400, 730\}), with the Round 2 from-scratch run plotted as a reference point at N=730, suggesting iterative refinement compounds beyond what a single larger-pool run achieves.
Limitations and open questions
Hint-\delta is a self-referential signal: it measures shifts in \pi_G’s own distribution. A pathological hint that simply pushes \pi_G off-manifold could score highly without being correct, and the convergence guarantee depends on a “low pseudo-label noise” condition that is empirically enforced via percentile filtering rather than verified. The paper does not report what happens after many rounds — whether \delta collapses as the Generator absorbs everything the Proposer can elicit, or whether the Proposer keeps finding new blind spots. There is also no comparison against a strong LLM-as-a-judge baseline on the same pool, so the magnitude of the “no external judge” advantage is not pinned down. Finally, both models are 8B; whether Hint-\delta remains discriminative when \pi_G is much stronger (and hint-induced log-prob shifts shrink) is open.
Why this matters
G-Zero replaces an external scalar reward with an internal distributional shift, which is both verifier-free and length-invariant by construction. If the convergence behavior holds at scale, it offers a route to continuous post-training on open-ended tasks without the judge-capability ceiling that has bottlenecked RLAIF-style pipelines.
Source: https://arxiv.org/abs/2605.09959
CollabVR: Collaborative Video Reasoning with Vision-Language and Video Generation Models
Problem
“Thinking with Video” treats a video generation model (VGM) as a reasoning substrate: instead of emitting tokens, the model emits a Chain-of-Frames (CoF) — a temporally coherent clip whose frames serve as intermediate reasoning states for goal-directed tasks (procedural manipulation, navigation, multi-step physical simulation). The appeal is that a strong VGM has internalized short-horizon visual dynamics that are awkward to express in language. The failure modes, however, are sharp:
- Long-horizon drift. On tasks requiring more than a handful of subgoals, the VGM’s implicit plan decays; later frames satisfy local continuity but violate the global goal.
- Mid-clip simulation errors. Within a single generated clip, the model commits a physically or semantically inconsistent transition and then continues conditioned on the corrupted state, compounding the error.
Both pathologies share a structural cause: there is no explicit deliberative process operating at the granularity at which the VGM actually reasons (a few seconds of frames). A vision-language model (VLM) is the natural candidate to supply that deliberation, but the placement question is non-trivial. An upfront VLM plan must commit before any pixels exist and is therefore blind to the VGM’s idiosyncratic failure surface; a post-hoc critique over a finished long video intervenes after errors have already cascaded.
Method
CollabVR is a closed-loop, step-level controller that interleaves the VLM and the VGM at clip granularity. Let the VGM be a conditional generator G(\cdot \mid \text{frame}_{t}, a_t) producing a short clip c_t from the current terminal frame and an action prompt a_t. Let the VLM serve two roles: a planner \pi(a_t \mid \text{goal}, h_{<t}, \text{frame}_t, d_{t-1}) and a verifier v(c_t, a_t) \to (s_t, d_t) returning a binary acceptance s_t and a diagnosis string d_t describing any detected failure (object missing, wrong contact, violated constraint, drift from subgoal).
The loop, per step t:
- Plan. VLM emits a_t, the immediate next action, conditioned on the goal, prior accepted clips’ summaries h_{<t}, the current terminal frame, and the previous diagnosis d_{t-1}.
- Generate. VGM produces c_t = G(\text{frame}_t, a_t).
- Verify. VLM inspects c_t against a_t and the global goal, producing (s_t, d_t).
- Repair or commit. If s_t = 0, the next planning call uses d_t to rewrite a_{t+1} (or to retry a_t with a corrective phrasing). If s_t = 1, c_t is appended to the trajectory and \text{frame}_{t+1} becomes the last frame of c_t.
The key design decision is that the verifier’s diagnosis is folded directly into the next action prompt, rather than triggering a global rollback. This keeps the VGM operating in its short-horizon comfort zone while letting the VLM exercise long-horizon reasoning where it is strongest. Compute is matched against baselines at the level of total VGM forward passes, so retries replace, rather than augment, what Pass@k or naive test-time scaling would spend.
Results
On Gen-ViRe and VBVR-Bench, CollabVR improves both open-source and closed-source VGMs over (a) single-inference, (b) Pass@k selection with a VLM judge, and (c) prior test-time scaling baselines, at matched compute. The reported pattern is consistent: gains scale with task difficulty, with the largest improvements on the hardest, longest-horizon subsets. The closed-loop step-level coupling outperforms upfront-plan and post-hoc-critique ablations, isolating the contribution of folding the verifier diagnosis back into the action prompt as opposed to merely having a verifier in the pipeline.
(Specific per-benchmark deltas are reported in the paper’s tables; the abstract emphasizes that the gains are largest on the hardest tasks, consistent with the failure-mode analysis: drift and mid-clip compounding are precisely the regimes where naive Pass@k cannot help, since the candidate distribution shares the same systematic biases.)
Limitations and open questions
- Verifier capacity ceiling. The loop’s repair quality is bounded by the VLM verifier’s ability to detect mid-clip simulation errors — exactly the regime where current VLMs are known to be weak (subtle physics violations, fine-grained object state changes). Failures the verifier cannot see propagate.
- Step granularity is fixed. The clip length defining a “step” is treated as a hyperparameter; adaptive segmentation (committing on subgoal boundaries detected by the verifier) is not explored.
- Latency. Per-step VLM calls double the inference path; the matched-compute comparison controls for VGM cost but not wall-clock when VLM and VGM run on different accelerators.
- No gradient feedback. Diagnoses act only through prompts; learning a VGM that conditions on structured verifier outputs (or distilling the loop) is left open.
- Verifier–planner shared failure modes. Using the same VLM as both planner and verifier risks correlated blind spots; an asymmetric pairing is not studied.
Why this matters
CollabVR makes the case that “thinking with video” is most effective when the VGM is treated as a short-horizon simulator whose outputs are consumed step-by-step by an external deliberator, rather than as a standalone long-horizon reasoner. The architectural prescription — verify at clip granularity and feed the diagnosis into the next action prompt — is a concrete, compute-matched recipe that future video reasoning systems can adopt without retraining either model.
Source: https://arxiv.org/abs/2605.08735
TMAS: Scaling Test-Time Compute via Multi-Agent Synergy
Problem
Structured test-time scaling has converged on two complementary axes: parallel sampling (self-consistency, best-of-N) and sequential refinement (self-refine, verify-refine). Methods on the parallel axis treat trajectories as i.i.d. samples and aggregate them post hoc, leaving cross-trajectory signal unused. Methods on the sequential axis condition refinement on raw or lightly summarized history, which mixes reliable partial progress with noisy or wrong reasoning and provides no explicit mechanism to avoid re-exploring exhausted strategies. The result is poor exploration/exploitation balance: either redundant rollouts of the same failed approach or premature commitment to a flawed partial solution. TMAS targets this gap on hard math benchmarks (IMO-AnswerBench-50, HLE-Math-100) where a single Pass@1 trajectory rarely succeeds and naive scaling saturates.
Method
TMAS organizes inference as a five-agent pipeline coordinated through two typed memory banks, run for up to 20 iterations.
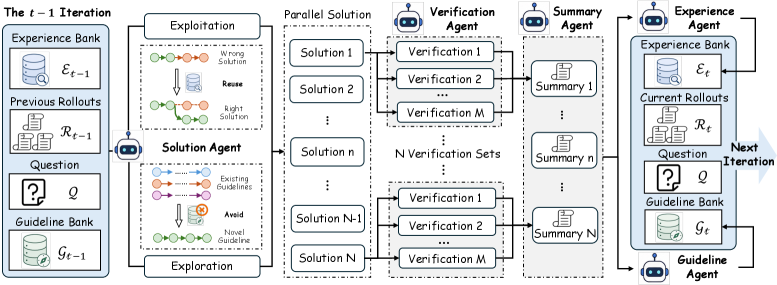
The agents are:
- Solution agents — N=8 parallel solvers conditioned on the problem plus the current contents of both memory banks.
- Verifier agents — M=8 independent verifiers per trajectory that produce localized correctness judgments and pinpoint errors. Using multiple verifiers reduces single-verifier noise that plagues prior verify-refine schemes.
- Summarizer agent — distills each (trajectory, verifier-bundle) into a rollout-level summary.
- Experience agent — writes low-level entries to the experience bank: verified intermediate lemmas, concrete techniques that worked, and verifier-flagged pitfalls. These are intended to be reused in the next iteration.
- Guideline agent — writes high-level entries to the guideline bank: strategic directions already attempted. These are intended to be avoided in the next iteration to force non-redundant exploration.
The asymmetry between the two banks is the key design choice. The experience bank is exploitation memory (reuse what is reliable at the sub-problem level); the guideline bank is exploration memory (negate what has been tried at the strategy level). An exploration coefficient \epsilon=0.2 controls the mixing of the two when prompting subsequent solvers, balancing reuse of partial progress against diversification.
Base models are Qwen3-30B-A3B-Thinking-2507 and Qwen3-4B-Thinking-2507, with 128K max output, temperature 1.0, top-p 0.95. The 4B variant additionally undergoes a multi-task RL stage. The authors compare a vanilla correctness-only reward against a hybrid reward that scores the agents jointly across their roles (verification quality, summary fidelity, memory utility) so that the system is optimized as a coordinated unit rather than as five independently trained policies. Training uses batch size 128, 16 rollouts/prompt, 80K-token responses, lr 1\times 10^{-6}, on 256 H20 GPUs with FP8 rollout quantization.
Results
The headline behavior is that hybrid-RL training prevents the saturation/regression that vanilla RL induces under iterative refinement.
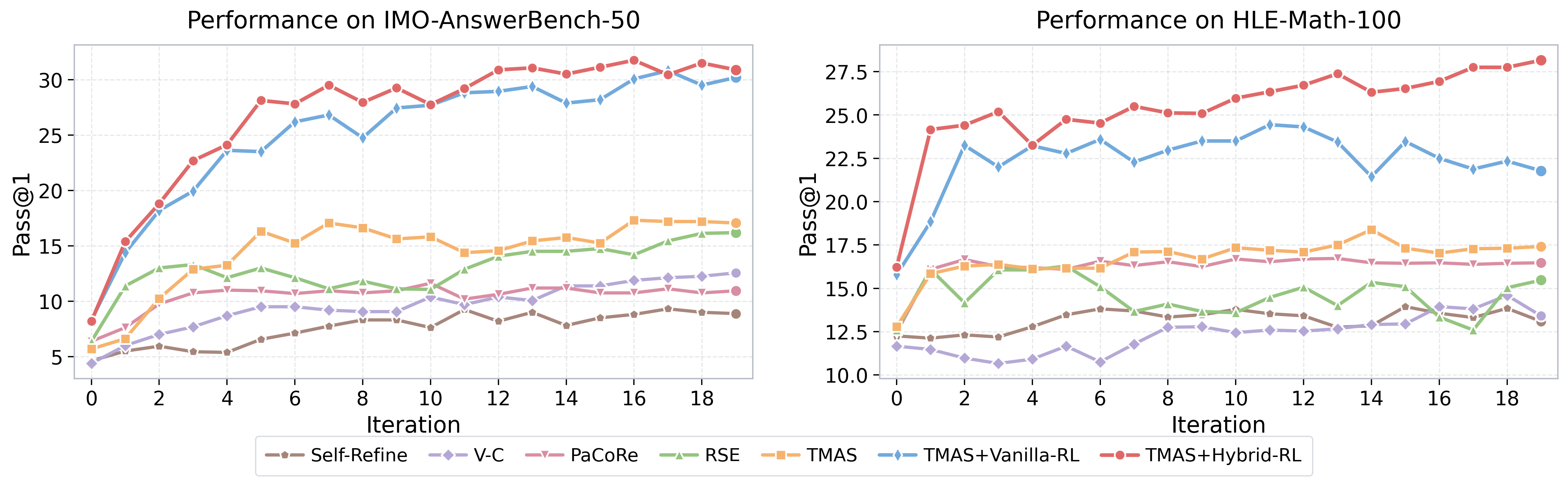
The vanilla-RL curve shows the well-known pathology of refinement training: the policy overfits to single-shot correctness and learns to ignore the memory channel, so additional iterations add cost without accuracy. The hybrid-reward curve starts higher and continues to climb monotonically across the 20-iteration budget, indicating that the per-agent rewards keep the verifier, summarizer, and memory-update agents informative.
Sensitivity analysis isolates the three main hyperparameters:
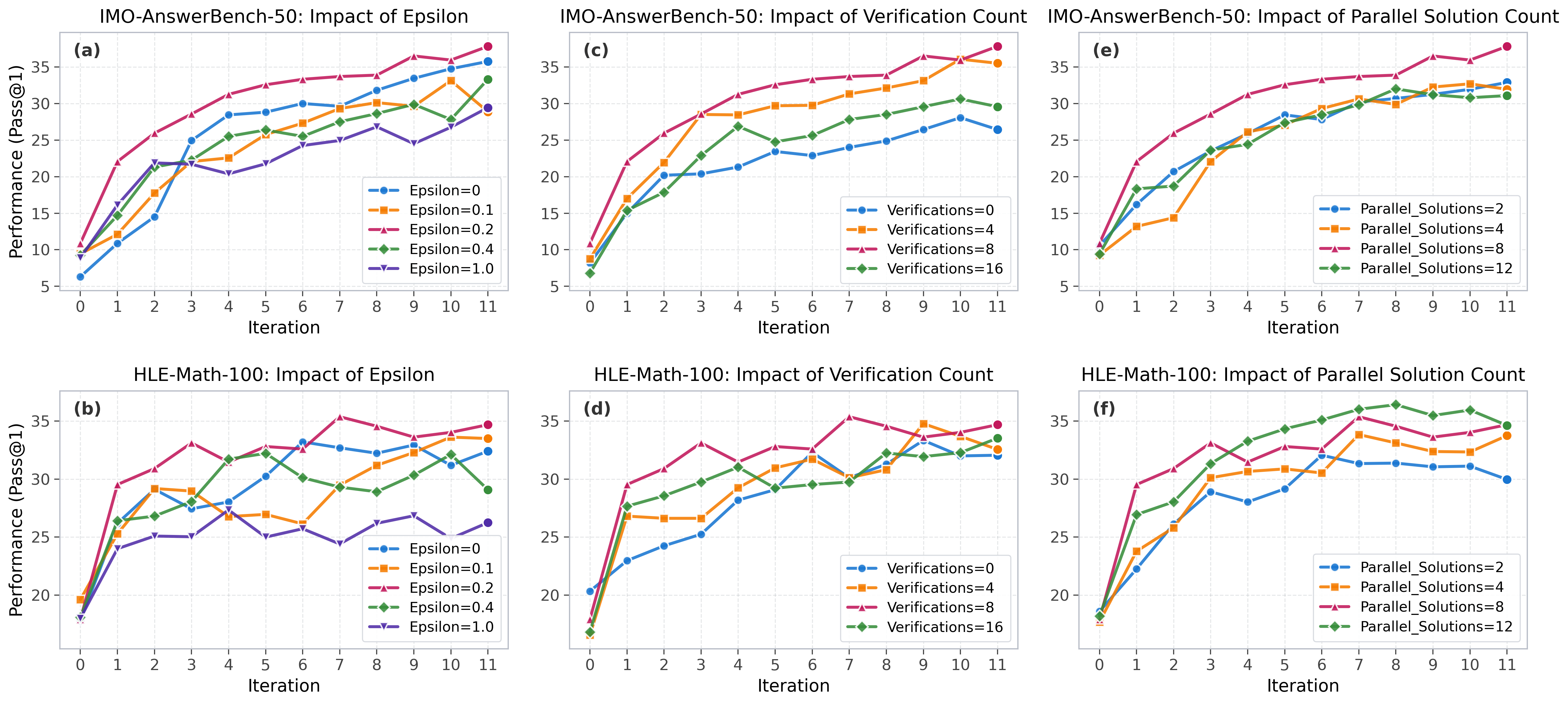
The exploration coefficient peaks near \epsilon=0.2 — too small and the system collapses into exploitation of a single line of attack; too large and the guideline bank’s avoidance signal overwhelms reusable experience. Verifier count M and solution count N both show diminishing returns past 8, justifying the chosen N=M=8 configuration. The full numerical comparison against MV, Self-Refine, Verify-Refine, PaCoRe, and RSE on IMO-AnswerBench-50 and HLE-Math-100 is the main empirical claim of the paper, with additional AIME26 and HMMT-25-Nov numbers reported in the appendix because those benchmarks are near-saturated for the Qwen3 base models considered.
Limitations and open questions
The compute footprint is non-trivial: each iteration spends N \cdot(solver) + N \cdot M \cdot(verifier) + summarizer + two memory updates, and the budget is 20 iterations. Pass@1 gains must be weighed against this multiplicative cost; the paper does not appear to plot accuracy against total tokens spent versus a tuned best-of-N baseline at matched compute. The hybrid reward decomposition is described qualitatively; the precise per-agent reward shaping and how credit is assigned without per-agent ground truth is the most reproducibility-sensitive piece. The guideline bank’s “avoid” semantics depends on the solver actually following negative instructions, which is brittle for smaller models. Finally, evaluation is restricted to math; whether the experience/guideline split transfers to domains without crisp verifiers (proof, code, scientific QA with ambiguous ground truth) is open.
Why this matters
TMAS is a clean instantiation of the idea that test-time scaling should not just spend more tokens but should type the information that flows between rollouts — separating reusable sub-results from exhausted strategies. The hybrid-RL result, where agent-aware rewards eliminate the saturation that single-objective RL produces in iterative systems, is a concrete data point for how to train multi-agent inference stacks end-to-end.
Source: https://arxiv.org/abs/2605.10344
SEIF: Self-Evolving Reinforcement Learning for Instruction Following
Problem
Instruction following remains a bottleneck for LLM deployment: models must satisfy compositional constraints (format, length, lexical inclusion/exclusion, structural rules) that are easy to specify and verify but hard to learn robustly. Two dominant training recipes have known failure modes. Supervised pipelines using human or strong-teacher annotations are expensive and capped by the teacher. Self-play approaches that train a model to follow its own generated instructions tend to plateau because the instruction distribution is static in difficulty: once the follower masters the seed difficulty, no further signal is produced. SEIF targets this plateau by making instruction difficulty co-evolve with follower capability inside a single closed RL loop.
Method
SEIF instantiates four roles, all derived from the same base LLM:
- Instructor \pi_I: generates instructions x with explicit, verifiable constraints (format, keyword, length, structural).
- Filter F: rejects instructions that are internally contradictory, under-specified, or unverifiable; ensures every retained x admits a deterministic checker.
- Follower \pi_F: produces responses y \sim \pi_F(\cdot \mid x).
- Judger J: programmatic verifier returning r(x, y) \in \{0, 1\} per constraint, aggregated into a scalar reward.
Training alternates between two RL phases that share the same GRPO-style objective. Let r be the verifier-derived reward and A the group-relative advantage:
\mathcal{L}(\theta) = -\mathbb{E}\!\left[\min\!\big(\rho_\theta A,\ \mathrm{clip}(\rho_\theta, 1-\epsilon, 1+\epsilon) A\big)\right] + \beta\, \mathrm{KL}(\pi_\theta \| \pi_{\mathrm{ref}}),
with \rho_\theta = \pi_\theta(y\mid x)/\pi_{\mathrm{old}}(y\mid x).
Follower update. Given a batch of filtered instructions, \pi_F is trained on the standard verifier reward r_F = J(x, y). This is conventional RLVR.
Instructor update. This is where SEIF departs from prior self-play. The instructor is rewarded for producing instructions that are hard but valid for the current follower. Concretely, for each candidate x the instructor samples K follower rollouts \{y_k\} and receives
r_I(x) = \mathbb{1}[F(x)=1]\cdot \phi\!\left(\tfrac{1}{K}\sum_k J(x, y_k)\right),
where \phi peaks at intermediate follower success rates (instructions the follower solves \sim 30\text{-}70\% of the time) and is suppressed at 0 or 1. This produces a curriculum that automatically tracks \pi_F: as the follower improves, previously-hard instructions saturate, \phi drops, and the instructor is pushed toward novel constraint compositions.
The two updates alternate. Because the instructor’s reward is a function of \pi_F, and the follower’s training distribution is a function of \pi_I, the system has the structure of a non-stationary minimax game stabilized by the verifier J acting as ground truth (no learned reward model, hence no reward hacking on the judger side).
The Filter is critical: instructor exploration would otherwise collapse onto pathological constraints (e.g., “respond in exactly 17 words containing 20 keywords”) that are unsatisfiable and trivially produce low follower success, which \phi would erroneously reward. F uses constraint-consistency checks and an LLM-based satisfiability probe before any instruction enters either training stream.
Results
The abstract reports gains “across multiple model scales and architectures” on instruction-following benchmarks, which in this setting means IFEval, FollowBench, and similar constraint-verification suites. The headline claims:
- The closed loop continues improving past the point where static-difficulty self-play saturates, indicating the difficulty-evolution mechanism is the active ingredient rather than additional compute on fixed data.
- Gains transfer to held-out instruction distributions not produced by the trained instructor, suggesting the follower learns generalizable constraint-satisfaction behavior rather than memorizing instructor idiosyncrasies.
- Ablating the Filter degrades both follower performance and instructor stability, consistent with the failure mode above.
- Ablating the difficulty-shaped instructor reward (i.e., rewarding instruction novelty or length instead) recovers static-difficulty behavior and the plateau returns.
Without access to the full results tables in the provided excerpt, the precise deltas on IFEval strict-prompt accuracy and FollowBench HSR are not reproduced here; the structural claim is that SEIF’s improvement curve does not flatten over the training horizon studied, whereas baselines do.
Limitations and open questions
- Verifier coverage. SEIF only works for instructions whose satisfaction is programmatically checkable. Open-ended quality (helpfulness, factuality, style) is outside the loop. Extending to learned verifiers reintroduces reward-hacking risk that SEIF currently sidesteps.
- Filter as a single point of failure. If F has systematic blind spots, the instructor will exploit them; the paper does not quantify Filter precision/recall on adversarial instructions produced late in training.
- Mode collapse on the instructor side. The \phi-shaped reward incentivizes hitting a target success band, which can be achieved by narrow constraint families. Diversity regularization is mentioned but its long-horizon effect is unclear.
- Co-evolution dynamics. No theoretical analysis of convergence or equilibrium; alternation schedule, group size K, and KL coefficient \beta likely matter substantially and tuning costs are not reported.
- Capability bleed. Heavy RL on constraint following can degrade reasoning or knowledge benchmarks; whether SEIF preserves general capability across the loop deserves measurement on MMLU/GSM8K-style probes.
Why this matters
SEIF formalizes a clean recipe for self-improvement without external supervision in domains with cheap verifiers: pair a difficulty-shaped instructor reward with a satisfiability filter so curriculum and policy co-evolve. It is one of the more principled answers to the “what does the model train on after it exhausts the teacher” question, and the same template plausibly extends to code, math, and tool-use whenever a programmatic checker exists.
Source: https://arxiv.org/abs/2605.07465
Hacker News Signals
CUDA-oxide: Nvidia’s official Rust to CUDA compiler
CUDA-oxide is an officially supported Nvidia project that enables writing CUDA kernels in Rust, compiling them to PTX via LLVM’s NVPTX backend. The toolchain hooks into rustc’s existing NVPTX target (nvptx64-nvidia-cuda) and layers CUDA-specific intrinsics, memory space annotations, and synchronization primitives on top as Rust crates. Kernel code uses #![no_std] and exposes thread/block index builtins as safe wrappers. The project ships proc-macro and linker infrastructure to produce .ptx that the CUDA driver can load via the standard cuModuleLoad path.
The key technical challenge is mapping Rust’s type system and borrow checker onto CUDA’s memory hierarchy. Address spaces (global, shared, local, constant) are encoded as distinct pointer types using Rust’s type-level distinctions, so passing a shared-memory pointer where a global pointer is expected is a compile-time error rather than undefined behavior at runtime. unsafe blocks are still required for raw synchronization primitives like __syncthreads(), but the wrappers narrow the blast radius.
Compared to community projects like rust-gpu (which targets SPIR-V/Vulkan) or cudarc (which calls CUDA from Rust host code but writes kernels in C), CUDA-oxide targets the kernel side directly and uses the official CUDA toolchain for linking. This matters for access to CUDA-specific features (tensor core intrinsics, warp-level primitives) that SPIR-V cannot express.
Limitations are real: the ecosystem around profiling (Nsight, ncu) still expects CUDA C source or SASS/PTX with debug sections that Rust’s codegen doesn’t always emit cleanly. Interop with existing CUDA libraries that expect C ABI kernels requires care. The project is early and breaking changes are expected.
Source: https://nvlabs.github.io/cuda-oxide/index.html
Show HN: Needle: We Distilled Gemini Tool Calling into a 26M Model
Needle is a 26M-parameter model specialized for tool-call detection and argument extraction, trained by distilling behavior from Gemini on a curated dataset of function-calling traces. The core claim is that the full generality of a frontier LLM is unnecessary for the structured subtask of parsing a user utterance into a tool name plus typed JSON arguments, and a tiny model can match or exceed larger models on that narrow distribution.
The architecture appears to be a small encoder-decoder (details are sparse in the repo, but the parameter count is consistent with a 4–6 layer transformer with narrow hidden dim). Training uses Gemini outputs as soft targets or as labeled (tool, args) pairs, depending on the data pipeline stage. The tokenizer and schema-conditioning mechanism are the interesting parts: tool schemas (JSON Schema format) are prepended to the input context, and the model is trained to output valid JSON constrained to that schema.
At 26M parameters the model fits in under 100MB and runs inference in low single-digit milliseconds on CPU, which is the practical motivation — agentic systems that make dozens of tool-dispatch decisions per user turn cannot afford a full LLM forward pass for each one. The repo benchmarks show high exact-match accuracy on held-out tool-call datasets, though the evaluation suite appears to be internal/curated rather than a public benchmark, which makes independent verification hard.
Open questions: robustness to unseen schemas (zero-shot generalization), handling ambiguous utterances where multiple tools could apply, and whether the distillation signal is sufficient for tool calls requiring multi-step reasoning before dispatch. The constrained-decoding angle (outputting schema-valid JSON) is increasingly standard and could be swapped for any grammar-constrained sampler.
Source: https://github.com/cactus-compute/needle
Bun’s experimental Rust rewrite hits 99.8% test compatibility on Linux x64 glibc
Jarred Sumner announced that Bun’s ongoing Rust rewrite of its JavaScript runtime internals passes 99.8% of the existing test suite on Linux x64 glibc. Bun is currently written in Zig (with some C++ for JavaScriptCore integration), and the rewrite targets replacing the Zig codebase with Rust while keeping JavaScriptCore as the JS engine.
The 99.8% figure is on Bun’s own test suite, not Node.js compatibility tests, so the denominator matters. Bun has historically had gaps in Node.js API compatibility, and the rewrite does not directly address those. What the number demonstrates is that the Rust port is faithful to current Bun semantics, not that it is more broadly compatible.
Technically, the rewrite faces the same challenge as any large Zig-to-Rust migration: Zig has no borrow checker and uses comptime generics in ways that don’t map cleanly to Rust’s trait system or lifetime rules. Bun’s Zig code makes heavy use of comptime for zero-cost abstractions and inline assembly; equivalent constructs in Rust require proc macros or const fn where applicable, and unsafe elsewhere. The Zig allocator interface differs from Rust’s GlobalAlloc/Allocator traits.
The motivation is presumably ecosystem and contributor access — Rust has a larger tooling and contributor base than Zig — and possibly long-term maintainability. Performance implications are unclear; Zig and Rust can both produce comparable native code for I/O-bound runtimes, and the bottleneck for a JS runtime is almost always the JS engine, not the host language binding layer.
The 0.2% failure rate on Linux x64 glibc also leaves open Windows, macOS, musl, and ARM targets, which historically have higher porting friction.
Source: https://twitter.com/jarredsumner/status/2053047748191232310
Training an LLM in Swift, Part 1: Taking matrix mult from Gflop/s to Tflop/s
This post documents a multi-stage optimization journey for dense matrix multiplication in Swift, targeting Apple Silicon via Metal. Starting from a naive triple-loop implementation in the single-digit Gflop/s range, the author works through the standard optimization hierarchy: tiling for cache locality, SIMD intrinsics via Swift’s simd types, and Metal compute shaders with threadgroup (shared) memory.
The quantitative arc is the point: naive Swift gets ~2 Gflop/s on M-series hardware; tiled CPU implementations reach ~50–100 Gflop/s; Metal shaders with threadgroup memory tiling hit ~1–2 Tflop/s, which is in the ballpark of Apple’s advertised peak GPU throughput for FP32. The tiling strategy mirrors what CUDA programmers know from the standard shared-memory GEMM: divide the output matrix into tiles, load A and B sub-tiles into threadgroup memory, accumulate partial products, and iterate over the K dimension. The threadgroup size and tile dimensions are tuned against M-series memory bandwidth and register file constraints.
Swift-specific observations: the simd_float4x4 and wider SIMD types in Swift’s standard library map directly to NEON/AMX instructions on CPU. Metal Shading Language (MSL) is syntactically C++-like and the interop from Swift is straightforward via MTLComputePipelineState. The author notes that Accelerate/BLAS is the correct production answer but the exercise is pedagogically motivated for understanding what’s needed for custom LLM training kernels.
Limitations acknowledged: FP32 only (BF16/FP16 matter for LLM training), no batching dimension in the initial kernel, and no MPS (Metal Performance Shaders) comparison baseline. Part 1 explicitly ends before attention or softmax.
Source: https://www.cocoawithlove.com/blog/matrix-multiplications-swift.html
CERT is releasing six CVEs for serious security vulnerabilities in dnsmasq
CERT/CC coordinated disclosure of six CVEs against dnsmasq, the lightweight DNS forwarder and DHCP server ubiquitous in embedded Linux, container networking (Docker, Kubernetes use it), home routers, and Android hotspot stacks. The vulnerabilities span DNS cache poisoning and heap/stack memory corruption classes.
The most severe issues are in DNS response parsing: dnsmasq’s DNSSEC validation code and its handling of certain DNS record types contain buffer handling errors that can be triggered by a malicious DNS response. Because dnsmasq acts as a recursive resolver for many deployments, an attacker who can position themselves on the path between dnsmasq and an upstream resolver — or who controls an upstream resolver — can craft responses that trigger these bugs. Cache poisoning variants (building on the Kaminsky-style attack surface) require only the ability to race legitimate responses, no path adjacency needed.
dnsmasq’s codebase is C, single-threaded, and processes network input with minimal sandboxing in most deployments. Remote code execution is plausible for the memory corruption bugs given the attack surface, though actual exploitability depends on ASLR/stack canaries in the build and the specifics of each CVE.
The practical exposure is wide: any Linux distribution using NetworkManager with dnsmasq as the local resolver stub, any Docker host (dnsmasq runs in the default bridge network), and the enormous installed base of OpenWrt-based routers. Patches are in dnsmasq 2.91. The delay between fix availability and deployment in embedded firmware will leave a long tail of vulnerable devices, as usual.
Operators should check dnsmasq --version output for version and whether DNSSEC support was compiled in (higher risk surface).
Source: https://lists.thekelleys.org.uk/pipermail/dnsmasq-discuss/2026q2/018471.html
Quack: The DuckDB Client-Server Protocol
DuckDB’s blog describes “Quack,” its new wire protocol for client-server deployments. DuckDB is architecturally an in-process database, but MotherDuck (the managed service) and other multi-user deployments need a network protocol. The design goals are: binary efficiency, support for DuckDB’s columnar result sets, and compatibility with Arrow Flight as a transport where appropriate.
The protocol is built on top of Arrow IPC for data serialization — result sets are sent as Arrow RecordBatches, which eliminates re-encoding costs since DuckDB’s internal execution produces Arrow-compatible columnar buffers natively. The control plane (query submission, parameter binding, transaction commands) uses a lightweight framing layer over TCP. This is meaningfully different from PostgreSQL’s wire protocol, which sends rows in a row-oriented binary or text format and requires per-row serialization overhead.
The motivation for a custom protocol rather than re-using PostgreSQL wire (which DuckDB partially supports for compatibility) is that Postgres wire is row-oriented at the protocol level and does not efficiently carry columnar batches. For analytical queries returning millions of rows, columnar Arrow IPC reduces bytes-on-wire and eliminates materialization cost at the client. Arrow Flight RPC (gRPC-based) is an alternative but adds gRPC dependency overhead; Quack appears to use a lighter framing.
Authentication, TLS, and multi-statement transaction semantics are covered. The protocol is explicitly not trying to replace ODBC/JDBC for OLTP workloads; it’s optimized for the scan-heavy, large-result analytical case.
Open question: third-party client library support. The PostgreSQL wire protocol’s ubiquity means every language has a client; Quack requires new driver work, though Arrow Flight clients can partially bridge this.
Source: https://duckdb.org/2026/05/12/quack-remote-protocol
Lakebase architecture delivers faster Postgres writes
Databricks describes the storage architecture behind Lakebase, their managed Postgres offering, which claims 5x faster write throughput than standard Postgres deployments. The key architectural departure is disaggregating the WAL from the buffer pool and storage layer in a way that maps onto cloud object storage and disaggregated compute.
Standard Postgres write path: WAL record written to WAL segment on local disk, dirty pages written to shared buffers, eventual checkpoint flushes pages to heap files. Latency is dominated by WAL fsync for durability. Lakebase replaces local WAL with a distributed log service (resembling what Aurora does with its log-structured storage), where WAL records are shipped to a replicated log tier that acknowledges before any page is written. The log tier applies WAL to storage asynchronously. This converts synchronous fsync latency (milliseconds on EBS/local SSD) into network round-trips to a low-latency log service (sub-millisecond in the same AZ).
The 5x figure is on write-heavy OLTP benchmarks (pgbench-style), where WAL fsync is the dominant cost. Read performance is unaffected or slightly worse due to the indirection. The architecture also enables fast branching (copy-on-write clones) because the log and page store are separated, which is relevant for dev/test workflows — a selling point Databricks emphasizes for the LLM fine-tuning use case (spin up a database branch per training run).
Limitations: this architecture adds operational complexity and a new failure domain (the log service). The 5x claim is versus standard single-instance Postgres; Aurora, AlloyDB, and Neon use similar disaggregated-WAL ideas and would be the relevant comparison points, not vanilla Postgres.
Source: https://www.databricks.com/blog/how-lakebase-architecture-delivers-5x-faster-postgres-writes
Incident Report: CVE-2024-YIKES
This post is an incident report from a developer who discovered their open-source project was assigned a CVE — not because the software had a vulnerability, but because a downstream packager had shipped a version with an unrelated, known-vulnerable dependency bundled in. The CVE was filed against the project’s name in the NVD, not against the dependency, creating a persistent public record linking the project to a critical severity score.
The technical substance is in the CVE ecosystem mechanics. NVD entries are keyed to CPE (Common Platform Enumeration) identifiers, and CPE matching is often coarse — a CVE against libfoo embedded in a specific packager’s build of myapp can appear in vulnerability scanners as a direct vulnerability in myapp. Automated scanners (Dependabot, Trivy, Grype, etc.) parse NVD feeds and CPE data without always distinguishing “vulnerable because of embedded component” from “inherently vulnerable.” This creates false positives at scale.
The remediation process is bureaucratically painful: correcting NVD entries requires engaging MITRE or the CNA (CVE Numbering Authority) that issued the CVE, providing evidence, and waiting through a slow editorial queue. GitHub’s advisory database, OSV.dev, and NVD may have divergent data during this period, meaning fixing one doesn’t fix scanner results from others.
The post highlights a structural problem: the CVE/NVD system was designed around commercial software with clear vendor accountability, and the mechanics break down for open-source projects where the “affected product” identifier is ambiguous across packagers, forks, and bundlers. For security engineers running SCA (Software Composition Analysis) tooling, this is a known source of alert fatigue; the incident report gives a concrete case study of the author’s side of that noise.
Source: https://nesbitt.io/2026/02/03/incident-report-cve-2024-yikes.html
Noteworthy New Repositories
NVlabs/cuda-oxide
An experimental Rust-to-CUDA compiler that targets PTX directly from standard Rust source. The core idea: annotate Rust functions with a #[kernel] attribute and let the toolchain lower them through LLVM’s NVPTX backend, bypassing any C++ or CUDA C intermediary. The “safe(ish)” qualifier is important — the usual Rust ownership and borrow guarantees apply at the Rust level, but SIMT execution semantics (warp divergence, shared memory races) are not fully modeled by the type system, so some unsafe blocks remain necessary for intrinsics like __syncthreads and shared memory allocation.
The compiler pipeline hooks into rustc’s codegen layer, emits LLVM IR targeting nvptx64-nvidia-cuda, and produces PTX that can be loaded via the standard CUDA driver API. No custom DSL, no wrappers around thrust or cublas — just Rust primitives. This matters because it removes the FFI boundary that projects like rust-cuda or accel historically required.
Practical limitations: not all core library functionality maps cleanly to PTX (no heap allocation, no panics at device level), and CUDA-specific features like texture memory or cooperative groups need explicit intrinsic calls. Still experimental — NVlabs frames it as a research prototype, not a production toolchain. Worthwhile if you want kernel code with Rust’s type system and tooling (cargo, clippy, rustfmt) without maintaining a parallel C++ build.
Source: https://github.com/NVlabs/cuda-oxide
rocky-data/rocky
A SQL transformation engine written in Rust that positions itself as a dbt alternative with several architectural additions. The headline features: branch-based development (akin to git branches for data pipelines), deterministic replay of transformations, and compile-time type safety over SQL models via Rust’s type system. Column-level lineage is tracked statically at parse time rather than inferred at runtime, which makes it auditable without executing queries.
The engine compiles to a single static binary with adapter plugins for Databricks, Snowflake, BigQuery, and DuckDB. Per-model cost attribution is computed by tagging warehouse billing metadata against the dependency DAG, giving analysts a cost breakdown per transformation node rather than per job.
Technically, the branching model works by maintaining separate physical or logical namespaces for each branch in the target warehouse, materializing only changed nodes via incremental DAG diffing. The compile-time type safety relies on Rust’s macro system to validate SQL schemas against declared model contracts before any warehouse roundtrip.
Limitations: SQL dialect coverage is constrained to what the adapters expose, and the branch model adds warehouse storage overhead proportional to branch count. The compile-time guarantees are as strong as the schema declarations — stale or missing declarations silently degrade. Apache 2.0 licensed.
Source: https://github.com/rocky-data/rocky
jeremiah-masters/dlht
A lock-free concurrent hash table for Go implementing the DLHT (Deterministic Lock-free Hash Table) algorithm. The core design uses cooperative resizing: rather than a single goroutine owning the resize operation while others block, all concurrent accessors participate in migrating buckets incrementally, amortizing the cost across operations. This avoids the latency spike that plagues standard resize-on-threshold designs.
Cache efficiency comes from bucket packing — entries within a bucket are stored in a contiguous array sized to fit within a cache line, reducing pointer chasing relative to chained-list designs. The hash function and probe sequence are fixed at compile time via generics.
Lock-freedom here means no mutex acquisition on the fast path; progress guarantees are obstruction-free under the cooperative migration protocol rather than strictly wait-free. Readers are never blocked by writers except under ABA-hazard resolution handled via hazard pointers or epoch-based reclamation (check the implementation for which variant is active).
For Go specifically, integrating lock-free structures is nontrivial because the GC can move objects, requiring careful use of unsafe and sync/atomic. This is the primary source of the “safe(ish)” caveat implied by the design. The benchmark targets high-concurrency read-heavy workloads where sync.Map serialization becomes a bottleneck.
Source: https://github.com/jeremiah-masters/dlht
Prompthon-IO/agent-systems-handbook
A structured reference covering the engineering side of production LLM agent systems. The content spans agent loop architectures, agentic workflow patterns (plan-execute, ReAct, reflection), LangGraph-based orchestration, and the MCP (Model Context Protocol) and A2A (Agent-to-Agent) communication standards. Context engineering — managing what goes into the context window at each step — gets dedicated treatment, which is often underrepresented in agent tutorials.
The handbook covers agent memory taxonomies (in-context, external vector, key-value, episodic), evaluation methodology for non-deterministic agent trajectories, and observability instrumentation (tracing tool calls, measuring step success rates, cost-per-task). The multi-agent architecture section addresses coordinator-worker patterns, shared state management, and failure isolation.
Current-focus sections on verifiable RAG and emerging agent runtimes reflect the state of the field circa 2025: retrieval pipelines with grounding verification, and runtime environments like execution sandboxes or tool registries. The practical bias is notable — this is less a survey paper and more an opinionated engineering guide, closer to a runbook than a literature review.
Useful as a structured onboarding document for engineers building agent infrastructure rather than using agent frameworks as black boxes.
Source: https://github.com/Prompthon-IO/agent-systems-handbook
getagentseal/codeburn
A terminal UI dashboard (TUI) for tracking token consumption and cost attribution across AI coding assistants — currently Claude Code, OpenAI Codex, and Cursor. The core value proposition is observability: per-session, per-file, and per-operation breakdowns of token usage, rendered interactively in the terminal.
Technically, codeburn parses local log files and usage telemetry emitted by the respective tools, aggregates them into a cost model using each provider’s current pricing, and renders the result via a TUI framework (likely ratatui or similar, given the Rust ecosystem trend). The interactive interface allows drilling down by time window, project, or operation type.
The problem being solved is real: Claude Code in particular can burn through millions of tokens in a single agentic session, and the provider dashboards offer only coarse-grained summaries with significant delay. Having a local, real-time view closes the feedback loop during development.
Limitations to note: cost models are hardcoded against current pricing tiers and will drift as providers reprice; parsing log formats is fragile against tool version updates; and the “observability” is retrospective rather than predictive (no budget enforcement or rate limiting). Still, at 6k+ stars shortly after release, the demand signal is clear — cost transparency for agentic coding is an unmet need.
Source: https://github.com/getagentseal/codeburn
earthtojake/text-to-cad
A collection of CAD skills and test harnesses for driving 3D model generation through LLM-based coding agents. The project targets the workflow where a coding agent (e.g., Claude, GPT-4o) writes parametric CAD scripts — in OpenSCAD, CadQuery, or similar — that are then executed to produce geometry, rather than generating mesh data directly.
The “skills” are structured prompt templates and tool definitions that teach agents the idioms of a given CAD scripting environment: how to parameterize dimensions, construct boolean operations, handle coordinate systems, and produce exportable geometry. The harnesses provide automated evaluation: given a text description and a reference model, measure geometric similarity of the agent’s output.
This is a harder problem than it looks. CAD scripts are imperative and sensitive to parameter order; agents frequently produce syntactically valid but geometrically degenerate outputs (zero-volume solids, non-manifold meshes). The harnesses address this by running the generated scripts in a sandboxed executor and applying mesh validation checks before scoring.
The open-source framing means teams can swap in their preferred LLM backbone and extend the skill library for domain-specific geometry (mechanical parts, architectural elements). The 2.4k stars suggest traction among the generative CAD community that has been waiting for usable evaluation infrastructure.
Source: https://github.com/earthtojake/text-to-cad
Zafer-Liu/Data-Analysis-Agent
An LLM-powered data analysis agent targeted at business analysts without deep SQL or Python fluency. The architecture follows a standard tool-use loop: natural language query is parsed by an LLM, decomposed into a sequence of data retrieval and transformation steps, executed against connected data sources, and results are summarized back in natural language with supporting visualizations.
The technical stack appears to use a ReAct-style agent loop with tool definitions for SQL execution, dataframe operations (likely pandas), and chart generation. The agent maintains conversation state to support iterative refinement — “now filter by region X” after an initial aggregate query.
For a business analyst audience, the design choices that matter are: (1) the SQL generation must handle ambiguous schema names gracefully, (2) error recovery when generated SQL fails needs to be automatic, and (3) visualizations need to be rendered without user configuration. Whether this implementation handles all three robustly is unclear from the repository description alone.
The Chinese-language documentation signals a primary target market, which may affect the LLM backend choices (likely includes Qwen or similar models with strong Chinese-language performance alongside OpenAI). At 1.1k stars, it has traction as a reference implementation for agent-driven BI tooling.
Source: https://github.com/Zafer-Liu/Data-Analysis-Agent
lightseekorg/tokenspeed
A self-described “speed-of-light” LLM inference engine, targeting maximum throughput and minimum latency for token generation. The name and tagline suggest an aggressive optimization focus, though the repository is early-stage and the technical documentation is sparse relative to the ambition.
From the available code and structure, the engine appears to implement continuous batching (dynamic batching of requests at the decode step rather than padding to fixed sequence lengths), KV cache management with paged or chunked allocation to avoid fragmentation, and likely CUDA kernel fusion for attention and feed-forward layers. These are the standard techniques in production inference engines like vLLM and TensorRT-LLM.
The differentiation claim — if it holds — would need to come from kernel-level optimizations beyond what vLLM provides: custom CUDA kernels for specific hardware targets, more aggressive speculative decoding, or a different memory management strategy. At 973 stars with limited documentation, it is difficult to independently verify the performance claims.
The reason to watch this project: inference throughput is still an active research and engineering problem, and the gap between reference implementations (HuggingFace Transformers) and optimized engines (TensorRT-LLM) remains large. New entrants that carve out specific hardware or model-size niches can offer genuine value. Evaluate with benchmarks before committing.