デイリーAIダイジェスト — 2026-05-11
arXiv ハイライト
Mean Mode Screaming: 1000層 Diffusion Transformer のための平均–分散分割残差
問題
DiT を数百層にスケールアップすると、標準的な loss 曲線では手遅れになるまで見えない失敗モードが露わになります。それはトークン表現がシーケンス全体で均一化し、トークン固有の内容を担う中心化された変動をネットワークが失う、突発的な平均支配崩壊です。著者らはその引き金を Mean Mode Screaming (MMS) と呼び、これが汎用的なオプティマイザの不安定性ではなく、深さ方向において残差ライターと行確率的 attention がどのように相互作用するかという構造的な帰結であると主張します。実用上の問題は、30–60 層でうまく機能するレシピ(Post-Norm + RMSNorm、LayerScale、ReZero)が、400 層以上では静かに失敗するか、性能を発揮しない点にあります。
幾何学と失敗のシーケンス
この分析は J=\frac{1}{T}\mathbf{1}\mathbf{1}^\top および P=I-J によるトークン軸分割に基づいており、X = \mu(X) + c(X) = JX + PX と分解します。すべての議論を駆動する二つの事実があります。
- 行確率的 attention は純粋平均成分を保存します: A\mu(X)=\mu(X)。
- 中心化成分は c(AX)=PAPX に支配され、収縮因子は \mu_{\text{eff}}(A)\triangleq\|PAP\|_2 です。
深い層で一度 \mu_{\text{eff}}<1 となると、attention は中心化された変動を厳密に収縮させ、残差ブランチのみがそれを補充できます。残差更新それ自体が平均コヒーレントになると、ネットワークは純粋平均の固定方向へと滑り込みます。
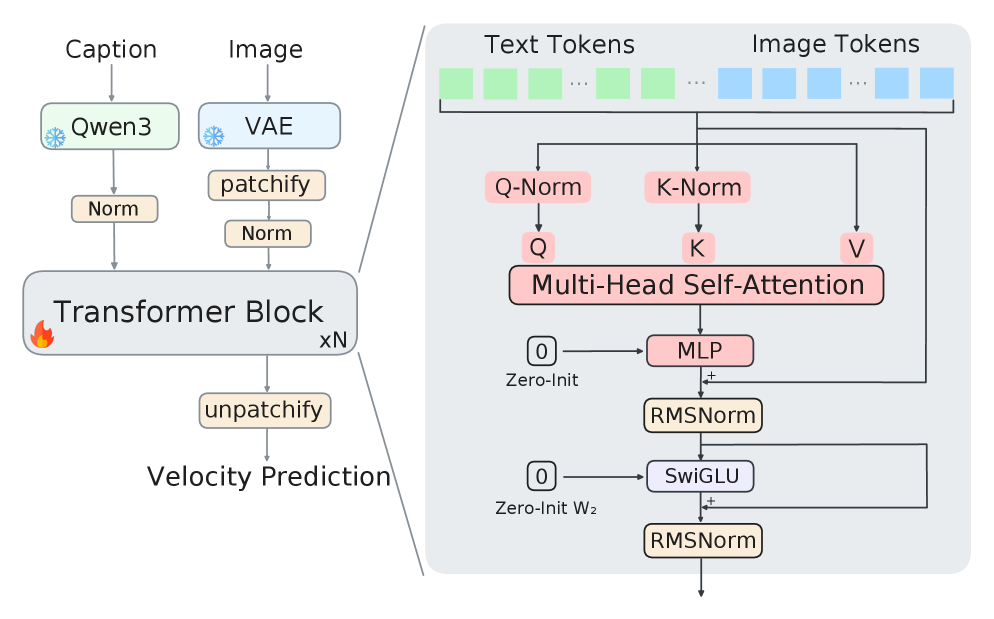
図2の右パネルは、L0–L384 の全深さにわたって \rho_T=\|\mu(X)\|_F/\|c(X)\|_F が単調に増加していることを示しており、これはまさに幾何学が脆弱性を予測する領域です。
メカニズム: 残差ライターにおける alignment-amplification
任意のトークンごとの線形ライター W(具体的には W_O と FFN の W_2)に対して、gradient \nabla_W\mathcal{L}=\sum_t \delta_t y_t^\top は、平均コヒーレント成分と中心化成分へと(交差項が和の下で消えることにより)厳密に分割できます。
\nabla_W\mathcal{L} = \underbrace{T\,\bar\delta\,\bar y^\top}_{\Delta W_\mu} + \underbrace{\sum_t \tilde\delta_t \tilde y_t^\top}_{\Delta W_c}.
平均項はランク1であり、\bar y, \bar\delta が打ち消し合わなくなると \mathcal{O}(T) でスケールします。中心化項は拡散的に和を取ります。alignment amplification を
\mathcal{A}-1 = \frac{\sum_{s\neq t}(\delta_s^\top\delta_t)(y_s^\top y_t)}{\sum_t \|\delta_t\|^2\|y_t\|^2} \approx (T-1)\,\underbrace{\mathbb{E}_{s\neq t}[\cos(y_s,y_t)\cos(\delta_s,\delta_t)]}_{\kappa},
と定義すると、MMS は順方向および逆方向の信号がトークン間で共整合する際の遷移 \kappa: 0 \to \mathcal{O}(1) です。一度 \kappa\to 1 となると、ランク1平均モードはコヒーレントな \mathcal{O}(T) の領域に達してライターに衝撃を与えます。さらに複合的な効果として、トークン間で value が均一化するにつれ、attention-logit の gradient が softmax Jacobian の零空間に落ち込み、Q/K は有用な信号を受け取れなくなります。つまりネットワークは attention を介した自己修正ができなくなります。
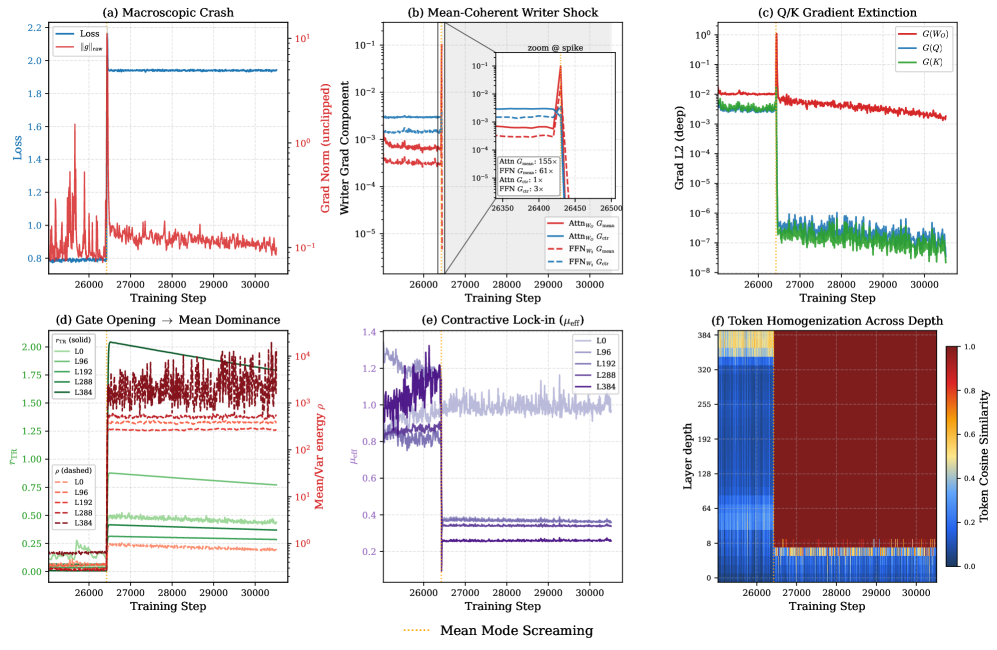
図3はトリガーを明確に示しています。グローバルな gradient ノルムのスパイクはほぼ完全に G_{\text{mean}}=\|\Delta W_\mu\|_F に現れており、G_{\text{ctr}} には同等の増幅が見られず、その後 Q/K の gradient が抑制されます。400 層実行のスパイクステップ t^\star=3400 において、実験的に活性化層は \mathcal{A}-1\approx 167、すなわち独立トークンのベースラインに対してライター gradient が約 13\times 増幅されており、式(6)で予測された絶対コヒーレンス飽和包絡線上に位置しています。Attn_WO と FFN_W2 の両方で同様の飽和近傍が現れており、attention 固有の話が否定され、失敗がライターインタフェースに起因することが確定します。
手法: MV-Split 残差
この修正は \Delta W_\mu を分離して減衰させる一方で、\Delta W_c を制限しません。Post-Norm のマージを、ブロックごと・チャンネルごとの学習可能なゲイン \alpha,\beta\in\mathbb{R}^D を用いた部分空間ルーティング残差に置き換えます。
Z_l = X_l + \beta\odot(PF_l) + \alpha\odot J(F_l - X_l), \qquad X_{l+1}=\text{RMSNorm}(Z_l).
正規化の前に射影することで二つの部分空間が切り離されます。
PZ_l = PX_l + \beta\odot(PF_l), \qquad JZ_l = (1-\alpha)\odot(JX_l) + \alpha\odot(JF_l).
中心化部分空間はゲイン \beta を持つ標準的な残差ストリームであり、平均部分空間は各特徴量ごとのリーキー積分器として、各層でトランク平均を 1-\alpha_d だけ収縮させます。重要なのは逆方向パスが同じ分割を継承することです。
\partial\mathcal{L}/\partial F_l = \beta\odot(PG_l) + \alpha\odot(JG_l),
そのため小さな \alpha は順方向の平均蓄積とランク1の \Delta W_\mu 成分の両方を減衰させる一方、中心化ブランチの gradient はゲイン \beta のまま保たれます。これが LayerScale および ReZero との構造的な違いであり、それらは単一の残差ゲインを適用するため \Delta W_\mu と \Delta W_c を必然的に同時に抑制してしまいます。マルチモーダル版では、残差制御パスで画像と text の平均が混合されないよう、J, P をセグメントごとに適用します。
結果
ImageNet-2012 の latent(固定 FLUX.2 VAE、Qwen3-0.6B テキストコンディショニング)上で学習した 400 層シングルストリーム DiT において、MV-Split は最初の 10k ステップ以内にクラッシュする不安定な Post-Norm ベースラインの発散崩壊を防ぎ、ベースラインのクラッシュ前の軌跡に近い挙動を保ちながら、トークン等方ゲーティング(LayerScale 型)制御よりも実質的に優れた性能を示します。同じ残差設計は 1000 層の実行にもスケールし、ImageNet の事前学習と約50k の厳選セットによる post-training を経て、一貫したテキストから画像へのサンプルを生成します(図1; 重みは https://huggingface.co/StableKirito/mvsplit-dit-1000l を参照)。
限界と未解決の問題
主要実験は競合システムではなく検証としての位置づけです。ImageNet スケールの latent、単一のバックボーンファミリー、提供されたセクションでは FID/CLIP の比較は報告されておらず、1000 層の実行は制御されたアブレーションではなくスケールのデモンストレーションです。メカニズム分析は等大きさの絶対コヒーレンスプロキシ \hat\kappa(上包絡線)に基づいており、より厳密な符号付きコヒーレント診断によって式(6)の予測的活用が精緻化されるでしょう。\alpha、\beta の初期化と learning rate/warmup スケジュールの相互作用は付録に委ねられており、異なる正規化選択(例えば極端な深さにおける QK-norm)や同じライター分解が成立する自己回帰型 transformer において MMS が再現するかどうかはまだ明らかではありません。
なぜこれが重要か
この論文は、DiT の深さスケーリングを律する特定の一つの不安定性——残差ライターにおけるランク1の平均コヒーレント gradient 蓄積——について厳密で反証可能な説明を与え、残りの残差信号を減衰させることなくそのモードを標的とする最小限の修正を提示します。alignment-amplification の法則が一般化するならば、深いトークン混合アーキテクチャ全般に対して、原則に基づいた診断指標(\hat\kappa、G_{\text{mean}}/G_{\text{ctr}})と設計ルール(平均と中心化の残差ゲインを分離する)を提供します。
Source: https://arxiv.org/abs/2605.06169
Listwise Policy Optimization: グループベースのRLVRをLLMレスポンスSimplex上のTarget-Projectionとして捉える
問題設定
グループベースのRLVR手法(GRPO、Dr.GRPO、DAPO、MaxRLなど)はいずれも、1つのプロンプトにつきK個のレスポンスをサンプリングし、グループ相対的なadvantageを計算して、PPOスタイルのsurrogateによってパラメータを更新します。これらの手法の違いは主にadvantageの正規化方法(グループの標準偏差\sigma_G、定数、グループ平均\mu_Gなど)にありますが、各手法が暗黙的に追いかけている分布が何であるか、またなぜ結果として得られる一次更新が安定するのかについて、統一的な説明は存在していませんでした。本論文は、このファミリー全体を有限レスポンスsimplex上の二段階target-projection手続きとして再定式化し、暗黙的な一次近似を明示的なprojectionステップに置き換えます。
Listwise分布と暗黙的なターゲット
プロンプトxに対してK個のサンプリング済みレスポンス\{y_k\}が与えられたとき、listwise分布を次のように定義します:
P_{\theta,k} = \mathrm{softmax}(s_\theta)_k, \quad s_{\theta,k} = \log\frac{\pi_\theta(y_k\mid x)}{\pi_b(y_k\mid x)},
これは\Delta^{K-1}上に定義されます。on-policyの点\pi_\theta=\pi_bにおいて、P_\theta = \mathbf{1}/Kとなります。著者らはこのsimplex上で局所的なproximal RL目的関数を定義します:
\max_{w\in\Delta^{K-1}} \hat J(w) = \sum_k w_k R_k - \tau D_{\mathrm{KL}}(w\,\|\,P_t),
ここでP_tは更新前のパラメータにおけるlistwise分布です。この唯一の最大化解はGibbsターゲットとなります:
w^*_k = \mathrm{softmax}(\phi)_k,\quad \phi_k = R_k/\tau + s_{t,k}. \qquad (8)
on-policy(P_t = \mathbf{1}/K)の場合、w^* = \mathrm{softmax}(R/\tau)となり、Proposition 1はGRPO(\tau=\sigma_G)、Dr.GRPO(\tau=1)、MaxRL(\tau=\mu_G)のそれぞれが、このターゲットを暗黙的な一次線形化として復元することを示しています。この観点では、advantageの正規化はtrust-regionの温度パラメータの暗黙的な選択にすぎません。
LPO:明示的なprojection
LPOは線形化されたPGステップの代わりに、式(6)の二段階更新を実行します:
- ターゲット計算。 式(8)によりw^*を閉形式で計算します。
- Projection。 選択したdivergence Dに対して\theta' = \arg\min_\theta D(w^*\,\|\,P_\theta)を解きます。

自然な2つの選択により、2つのバリアントが得られます:
- \mathrm{LPO}_{\mathrm{fwd}}:forward KL D_{\mathrm{KL}}(w^*\,\|\,P_\theta) = -\sum_k w^*_k \log P_{\theta,k} + \text{const}、すなわちK個のレスポンスに対する重み付きlistwiseクロスエントロピーであり、mass-coveringな性質を持ちます。
- \mathrm{LPO}_{\mathrm{rev}}:reverse KL D_{\mathrm{KL}}(P_\theta\,\|\,w^*)、mode-seekingな性質を持ちます。
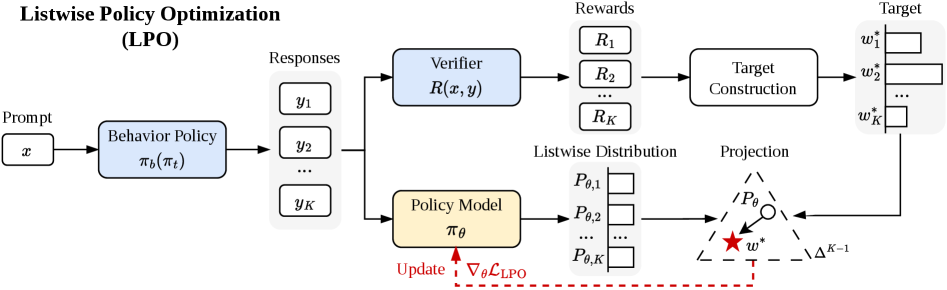
projectionのgradientは有界であり、グループ全体でゼロサムとなります(w^*とP_\thetaはいずれもsimplex値であるため、s_\theta空間におけるgradientの和はゼロになります)。また自己修正的な性質を持ち、P_\theta\to w^*となるにつれてgradientは消えます。Theorem 2は単調改善の下界を与えます:projectionが\mathrm{TV}(P_{t+1}, w^*)\le\epsilon_{\mathrm{proj}}を達成し、|R_k|\le R_{\max}であれば、
\hat R(P_{t+1}) \ge \hat R(P_t) + \tau\bigl[D_{\mathrm{KL}}(w^*\|P_t) + D_{\mathrm{KL}}(P_t\|w^*)\bigr] - 2R_{\max}\epsilon_{\mathrm{proj}}.
Jeffreys-divergenceによるターゲットゲインは非負であり、w^*\ne P_tのとき厳密に正となります。これは線形化されたsurrogateにおいてのみ降下を保証するPGとは対照的です。
実装の骨格
各プロンプトに対して:
Sample K responses from pi_t; receive rewards R_k.
Compute s_{t,k} = log pi_t(y_k|x) - log pi_b(y_k|x).
phi_k = R_k / tau + s_{t,k}
w_star = softmax(phi) # detached
For minibatch step over k:
s_{theta,k} = log pi_theta(y_k|x) - log pi_b(y_k|x)
P_theta = softmax(s_theta)
loss = D(w_star, P_theta) # forward or reverse KL
backprop温度パラメータ\tauは各ベースライン(\sigma_G、1、\mu_G)に合わせて設定されるため、得られる改善はprojectionによるものであり、温度チューニングによるものではありません。
実験結果
LPOは、論理推論(Countdown-34/4)、数学(MATH → AIME24/25、AMC23、MATH500、Minerva、Olympiad)、コード(PRIME)、マルチモーダル幾何(Geometry3k)のタスクに対して評価されており、バックボーンは1.5Bから14B(Qwen3-1.7B/4B/8B/14B-Base、Qwen2.5-VL-3B-Instruct)です。
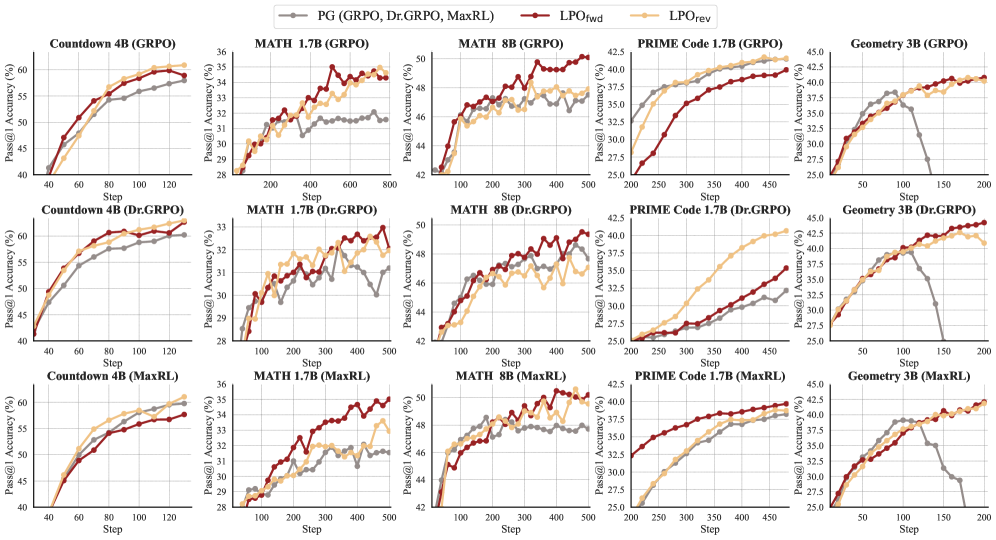
3つのベースライン温度レジームおよび4つのタスクドメインすべてにおいて、\mathrm{LPO}_{\mathrm{fwd}}と\mathrm{LPO}_{\mathrm{rev}}はいずれも、学習全体を通じて対応するPGベースラインをPass@1で上回ります。\tauは各PGの対応手法と同一に保たれているため、学習曲線は線形化されたPGステップを厳密なprojectionに置き換えた効果を単独で示しています。reverse KLバリアントはw^*に対するmode-seekingの性質から鋭い傾向があり、forward KLはより保守的です。いずれもsimplex値のprojectionが意味する有界なゼロサムgradientを受け継いでいます。
制限と未解決の問題
- 解析はプロンプトごとのローカルな分析であり、プロンプト間の相互作用や単一更新ステップを超えたoff-policyな再利用は特徴づけられていません。
- レスポンスsimplexは固定のKを持ちます。K\to\inftyの極限では標準的なKL正則化RL目的関数が回復されますが、有限Kのバイアスは定量化されていません。
- 評価されているのはforward/reverse KLのみであり、フレームワークは任意のdivergence(例:\alpha-divergence、\chi^2)を許容しますが、どのdivergenceがどのようなreportスパーシティの下で最適かは未解決です。
- 改善の下界は\epsilon_{\mathrm{proj}}に依存しますが、実際にはSGDのステップ数と学習率を通じてのみ暗黙的に制御されます。
- クローズドソースのRLVRレシピ(例:完全なエンジニアリングを施したDAAPO)との最終的な絶対精度の比較は報告されておらず、比較はapples-to-applesですが範囲が限定的です。
なぜこれが重要か
本論文は、グループベースRLVRにおけるadvantage正規化の選択がtrust-regionの温度として振る舞う理由についての明快な幾何学的説明を提供しており、標準的なPGステップが閉形式のGibbsターゲットを許容する厳密なprojectionの一次線形化にすぎないことを示しています。線形化を明示的なdivergence最小化に置き換えることで、再チューニングを必要とせずに単調改善の保証と一貫した実験的な改善が得られます。これは、advantage正規化のトリックを新たに追加するよりも原理的なアプローチです。
Source: https://arxiv.org/abs/2605.06139
LLMによるLLMの改善:Test-Time ScalingのためのAgentic Discovery
問題設定
Test-time scaling(TTS)——best-of-N、self-consistency、early stopping、adaptive branching、speculative pruning——は現在、手作業でチューニングされたヒューリスティックの寄せ集めに過ぎません。各手法は幅-深さの配分空間の一断面を選択し、閾値を手動でコーディングしています。著者らは、設計空間が十分に広大であるため、人間の直感では大きなPareto改善の余地が残されていると主張しています。そして、LLMエージェントが最適化すべき対象は単一のヒューリスティックではなく、ヒューリスティックを安価に探索できる環境であると述べています。
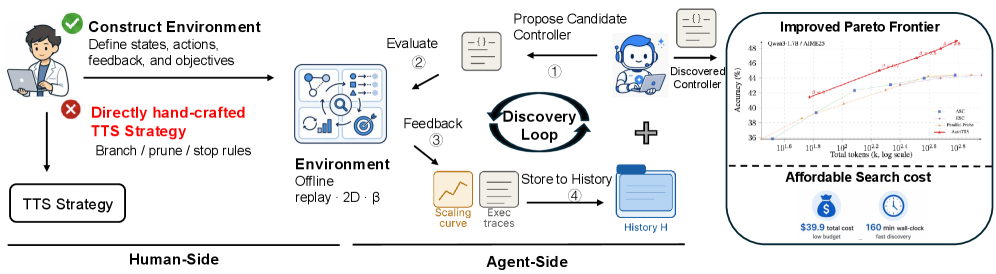
形式化:予算付きMDPとしての幅-深さ制御
本論文は、適応的推論を状態 s_t = (q, m_t, I_t, \ell_t, \Omega_t) 上のコントローラ合成として定式化しています。ここで m_t はインスタンス化されたブランチ数、I_t \subseteq [m_t] はアクティブ集合、\ell_{t,i} はブランチ i の深さ(\Delta トークンの固定長プローブ区間単位)、\Omega_t は明らかにされたプローブ回答 (i, k, \omega_{i,k}) を保持します。コストは次のように累積されます:
\mathrm{Cost}(s_t) = \sum_{i=1}^{m_t} \ell_{t,i} + \kappa_{\mathrm{probe}} |\Omega_t|,
許容されるアクションは \{\texttt{BRANCH}, \texttt{CONTINUE}(i), \texttt{PROBE}(i), \texttt{PRUNE}(i), \texttt{ANSWER}\} であり、グローバル予算 B に従います。BRANCH は新しいチェーンを開き、1区間だけ実行します。CONTINUE はアクティブなブランチを \Delta トークン延長します。PROBE はブランチを進めずに現在の中間回答 \omega_{i,\ell_{t,i}} を明らかにします。PRUNE はブランチを非アクティブ化しますが履歴は保持します。ANSWER は集約を起動します。
この定式化は、既存手法を2次元の幅-深さ空間上の制約付きポリシーとして包摂しています。
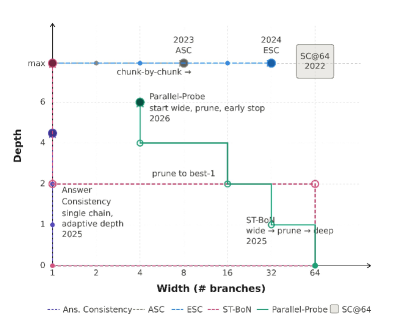
SC@64は最大幅・完全深さのコーナーに位置し、ASCとESCは固定された完全深さで幅を適応させ、Answer Consistencyは単一チェーン上で深さを適応させ、ST-BoNは幅広く展開してからプルーニングします。AutoTTSは完全な2次元空間を探索します。
手法:AutoTTS
探索を実行可能にする3つの設計上の選択があります:
オフラインreplay環境。 各 (q, \text{model}) ペアに対して、温度0.7で N=128 個のトラジェクトリを事前サンプリングし、それぞれを \Delta = 500 トークンの区間に分割します。ブランチのプレフィックス z_{i,k} とプローブ信号 \omega_{i,k} は事前計算してキャッシュされます。候補コントローラの決定はこのreplayマトリックスへのインデックスとなり、discovery中にLLMを呼び出す必要はありません。各コントローラは128のプールからサブサンプリングすることで64回評価され、分散を低減します。
Betaパラメータ化。 エージェントが生の閾値を出力すること(\mathcal{Q}_{\text{search}} に過学習する)を避けるため、ポリシーは正規化された \beta 値によってパラメータ化されます。エージェントはコードで定義されたコントローラ \pi(\cdot \mid s, \beta) を記述し、ここで \beta は予算とモデルをまたいで転移する形でブランチング、プルーニング、停止の決定を制御します。
実行トレースフィードバック。 explorerのLLMにスカラーの精度/コストのみを返すのではなく、各評価ではコントローラが失敗した理由の詳細なトレース(例:深さ k で最終的に正解するブランチをプルーニングした、発散するチェーンで予算を使い果たした、プローブが少なすぎた)を返します。これにより、エージェントのタスクがブラックボックスのハイパーパラメータ探索からデバッグに近いものへと変換されます。
discovery loopは explorer LLM として Claude Code を5ラウンド使用します。\mathcal{Q}_{\text{search}} はAIME24であり、\mathcal{E}_{\text{search}} はQwen3-{0.6B, 1.7B, 4B, 8B}全体のAIME24環境の和集合です。\mathcal{E}_{\text{search}} 上の精度を最大化する単一のコントローラが固定され、転移されます。
結果
発見されたコントローラは、discovery中もモデル選択中も一度も見ていない保留済みのAIME25およびHMMT25環境で評価されます。replay ベースの評価により、1回のオフラインのトラジェクトリパスのコストで、1ラウンドあたり数千回のコントローラ評価が可能になります。同じ探索を行う場合、候補1つあたりオーダー 64 \times |\mathcal{E}_{\text{search}}| のライブLLMロールアウトが必要になります。4つのモデルスケールにわたるAIME25/HMMT25への保留済み転移が中心的な実証的主張であり——AIME24のみで最適化された発見済みコントローラが新しいベンチマークに汎化し、モデルごとの再チューニングなしに0.6B-8BのQwen3レンジ全体で再利用されます。
制限と未解決の問題
- replay環境は温度0.7、\Delta = 500 でトラジェクトリ分布を固定します。温度スケジューリング、可変区間長、またはブランチの再サンプリングから恩恵を受けるコントローラは表現できません。
- N = 128 の事前サンプリングされたトラジェクトリが達成可能な幅の上限となります。ブランチ129を要求するコントローラにはreplayデータがありません。
- プローブ信号 \omega_{i,k} はLLMが生成する中間回答であり、ベースモデルのキャリブレーション誤差を継承します。\Omega_t を条件とするプルーニング決定はそのバイアスを伝播させます。
- discoveryはAIME24に限定されており、\mathcal{Q}_{\text{search}} がコードや長文脈QAである場合に同じエージェントループが質的に異なるコントローラを生成するかどうかは未検討です。
- Claude Code の5ラウンドは小さな探索予算であり、探索と評価のPareto frontierは特性化されていません。
なぜこれが重要か
本論文の貢献は方法論的なものです。オフラインのreplay環境と安価で決定論的な評価を可能にするパラメータ化を構築することで、著者らはTTSアルゴリズムの設計を手作業のヒューリスティック演習からLLMエージェントがエンドツーエンドで実行できる探索問題へと変換しました。これは、LLMの自己改善におけるボトルネックがオプティマイザそのものではなく環境の構築にあるという、より広いパターンの具体的な事例です。
Source: https://arxiv.org/abs/2605.08083
Anisotropic Modality Align
対照的マルチモーダルエンコーダ(CLIPスタイル)は、MLLMがテキストのみのデータで学習しながら推論時に画像embeddingを受け取れるようにする「橋渡し」として、ますます広く使われています。これが機能するのは、テキストと画像のembeddingが共有空間内で互換性を持つ場合に限られます。しかし、根強く残るモダリティギャップは、それらが互換でないことを示しています。本論文は、このギャップが幾何学的に実際には何であるかを問い、それがグローバルな平行移動でも汎用的な分布のミスマッチでもなく、既に共有された支配的な幾何構造の上に乗った低ランクの異方性残差であることを明らかにしています。
ギャップは一般的な認識とは異なる
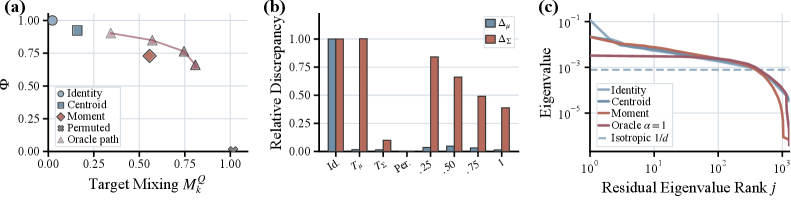
100万組の画像-テキストembeddingペアを用いて、著者たちは中心化された共分散行列 \Sigma_x と \Sigma_y を比較しています。重要な診断指標が2つあります。第一に、スペクトル相関 C_\lambda = \mathrm{corr}(\log\lambda(\Sigma_x), \log\lambda(\Sigma_y)) = 0.845, すなわち、2つのモダリティは支配的な方向にわたって分散をほぼ同様に配分しています。第二に、主部分空間のオーバーラップ O_q = \tfrac{1}{q}\,\|(U_x^q)^\top U_y^q\|_F^2 はランダムベースライン q/d を大きく上回っており、q=128 において O_{128}=0.441(q/d=0.100 に対して)となっています。
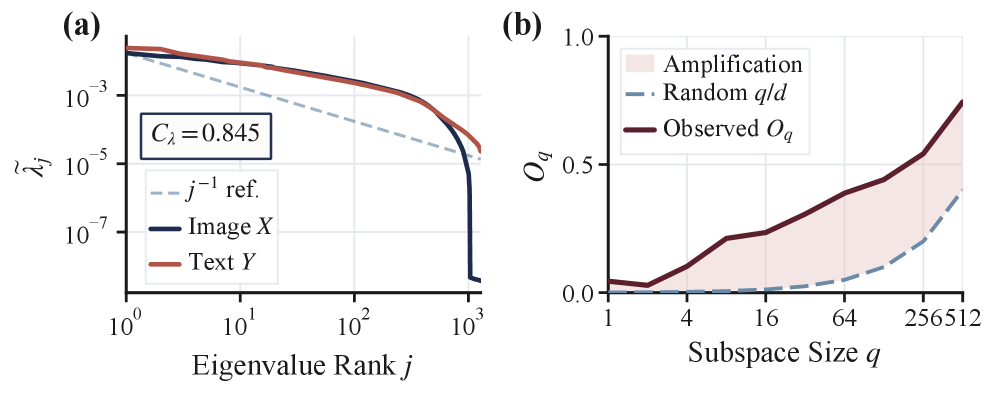
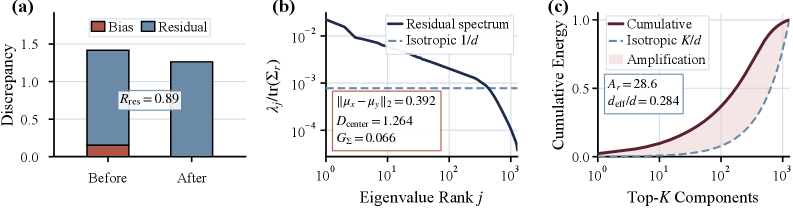
すなわち、支配的な方向は共有されています。では残るものは何でしょうか?平均中心化の後でも、残差クロスモーダルの不一致は依然として大きく、その共分散スペクトルは等方性から大きく外れており、エネルギーは少数の方向に集中しています。報告された異方性比は A_r=28.6、有効次元比は d_{\mathrm{eff}}/d = 0.284 です。
これは従来の修正手法を再定式化するものです。単純な重心シフト(C3など)は等方性に見える小さな部分しか修正できず、積極的なターゲット置換戦略はソースの意味的対応を破壊してしまいます(図3)。修正すべき正しい対象は、小さな異方性残差部分空間です。
AnisoAlign
本手法は、ドリフトし得るモダリティ固有の基底を推定する代わりに、共有フレームを固定します。\mu_t,\mu_i\in\mathbb{R}^d を経験的平均、\Sigma_t,\Sigma_i を中心化された共分散とします。結合構造行列を \Sigma = \Sigma_t + \Sigma_i + \lambda I, と定義し、Q_U\in\mathbb{R}^{d\times r} をその上位 r 個の固有ベクトルとします。すると \mathbb{R}^d = U\oplus V(U=\mathrm{span}(Q_U))となり、任意のembeddingは z_U = Q_U Q_U^\top z, \qquad z_V = z - z_U. \tag{1} と分解されます。U はギャップが集中する共有異方性部分空間であり、V は(ほぼ等方性の)補空間です。すべてのアラインメント操作はこの固定された分解の下で行われます。U 内では少数の異方性方向に沿ってターゲット分布に合わせる積極的な修正を、V ではソースの意味的構造を保持するための最小限の修正を行います。これは本論文が明示する原則、すなわちターゲットモダリティの分布にアラインしつつソースモダリティの意味的構造を保持する、を体現するものです。単一のグローバル変換でトレードオフをとるのではなく、2つの目的を直交する部分空間に分離することで実現しています。
経験的幾何構造
エンコーダとして LLM2CLIP-OpenAI-L-14-336、LLMバックボーンとして Llama-3-8B-Instruct を用い、著者たちは10Kのペアサンプルにおいて、Text(生テキストembedding)、C3、ReAlign、AnisoAlign を比較しています。画像をターゲットとして使用しています。
- 重心不一致 \Delta_\mu(T) = \|\mu_z - \mu_x\|_2:Text 0.393、C3 0.276、ReAlign と AnisoAlign はともに \approx 0.012。すなわち、平均アラインメントはいずれの部分空間手法でも本質的に解決されています。
- 局所サポート互換性。対称 k-NN 浸透度 M_k^Z(変換されたソースがターゲット近傍に存在するか)と M_k^X(ターゲットが変換されたソース近傍に存在するか)で測定:
- C3:M_k^Z=0.410、M_k^X=0.075 — 浸透はまばらで、カバレッジは低い。
- ReAlign:0.357 / 0.305 — バランスが取れている。
- AnisoAlign:0.372 / 0.337 — 浸透とカバレッジのバランスが最も良い。
- 残差共分散スペクトル:Text と C3 は顕著な異方性残差方向を保持しており、AnisoAlign は最も弱い構造的残差を示しています。
この診断結果が示すメッセージは、従来手法は残差を過小修正する(C3)か、ソース構造を圧縮してターゲットに適合させる(V 内での ReAlign 的な過剰修正)かのいずれかであるのに対し、強い修正を U に限定することで、実際に差異が生じている箇所でターゲットに適合させられるということです。
限界と未解決問題
提供されたセクションには MLLMの下流タスクの数値(Q2〜Q6は参照されているが示されていない)が報告されておらず、改善された幾何構造から VQA・キャプション精度への変換については、論文全体から確認する必要があります。r と \lambda の選択は抜粋中では分析されておらず、どちらも残差のどの程度を異方性として扱い、どの程度のエネルギーを保持するかを制御します。共有フレームの仮定は、LLM2CLIP/CLIPライクなエンコーダで見出されたスペクトル互換性に基づいており、支配的な幾何構造がより乖離し得る音声-テキストや動画-テキスト空間でも成立するかどうかは未解決のままです。最後に、この分析は純粋に2次モーメントに基づいており、U 内での高次の分布的ミスマッチ(歪度、モード分離)は線形射影では直接対処されません。
なぜこれが重要か
モダリティギャップが本質的に共有された幾何構造の上に乗った低ランク異方性残差であるならば、単一モーダルデータでMLLMを学習することは、表現学習の問題ではなく、線形代数の問題として適切に定式化できます。つまり、少数の方向を修正し、残りはそのままにするということです。固定フレーム分解は、対照的バックボーンを再学習することなく、これを実現するためのクリーンかつエンコーダに依存しないレシピを提供します。
Source: https://arxiv.org/abs/2605.07825
TextLDM: 連続潜在拡散による言語モデリング
問題設定
VAE潜在空間においてflow matchingを用いたDiffusion Transformerは、視覚生成における支配的なレシピとなっています。同じレシピがテキストにもきれいに転用でき、合成と理解を統一するアーキテクチャが実現できるかどうかは、いまだ未解決の問題です。これまでの連続潜在テキスト拡散の試み(Lovelace et al.、PLAID/TEncDM)は、自己回帰ベースラインおよび離散拡散手法(例:LLaDA)の双方に対して性能が劣っており、ボトルネックが拡散の目的関数にあるのか潜在空間そのものにあるのかが明確ではありませんでした。TextLDMは、問題は潜在空間にあると主張し、その根拠を提示しています。すなわち、再構成のみを目的として最適化されたVAEは、ノイズ除去に適したマニフォールドを生成しないのであり、事前学習済みLMとのREPAによる潜在空間のアラインメントがそのギャップを埋めるとしています。

手法
TextLDMは、画像向けのStable Diffusion / DiTを踏襲した2段階の構成を持ちます。
Stage 1 — TextVAE。 Qwen3のトークナイザーで\mathbf{x}=(x_1,\dots,x_N)にトークン化します。Transformer エンコーダE_\phiは各位置に対角ガウス事後分布を生成します: q_\phi(\mathbf{z}_i\mid \mathbf{x}) = \mathcal{N}(\boldsymbol\mu_i, \boldsymbol\sigma_i^2), 再パラメータ化されたサンプルは\mathbf{z}_i = \boldsymbol\mu_i + \boldsymbol\sigma_i\odot\boldsymbol\epsilonです。重要な点として、このマッピングは長さについて一対一対応となっており、各トークンが一つの潜在変数\mathbf{z}_i\in\mathbb{R}^dを持ちます。これは、より短い潜在系列に圧縮するPLAID/TEncDMとは異なります。TransformerデコーダD_\psiはクロスエントロピーのもとで非自己回帰的にトークン分布を再構成します。学習は、再構成CE、事後分布に対するKL正則化項、そして鍵となる要素であるREPAアラインメントの組み合わせによって行われます。REPAアラインメントは、エンコーダの隠れ状態を凍結されたQwen3-1.7Bの特徴量に一致させるものです。VAE学習時における入力系列のランダムな切り詰めにより、エンコーダが可変長に対応できるようになります。これは、下流のDiTがコンテキストとターゲットのセグメントを独立してエンコードするために重要です。
Stage 2 — TextDiT。 視覚向けのものと同一のアーキテクチャを持つ標準的なDiTが、潜在空間においてflow matchingを実行します。ノイズのないコンテキスト潜在変数\mathbf{z}^{\text{ctx}}とノイズの乗ったターゲット潜在変数\mathbf{z}^{\text{tgt}}_tが連結され、ネットワークは\mathcal{N}(0,I)をデータ条件付き分布へ輸送する速度場v_\thetaを予測します。標準的なFM lossは以下の通りです: \mathcal{L}_{\text{FM}} = \mathbb{E}_{t,\mathbf{z}_0,\mathbf{z}_1}\big\|v_\theta(\mathbf{z}_t,t,\mathbf{z}^{\text{ctx}}) - (\mathbf{z}_1-\mathbf{z}_0)\big\|^2, ここで\mathbf{z}_t=(1-t)\mathbf{z}_0 + t\mathbf{z}_1です。無条件生成ではコンテキストを除去します。学習時にターゲットがコンテキストへリークするのを防ぐため、全系列をエンコードしてスライスするのではなく、コンテキストとターゲットはE_\phiによって独立にエンコードされます。
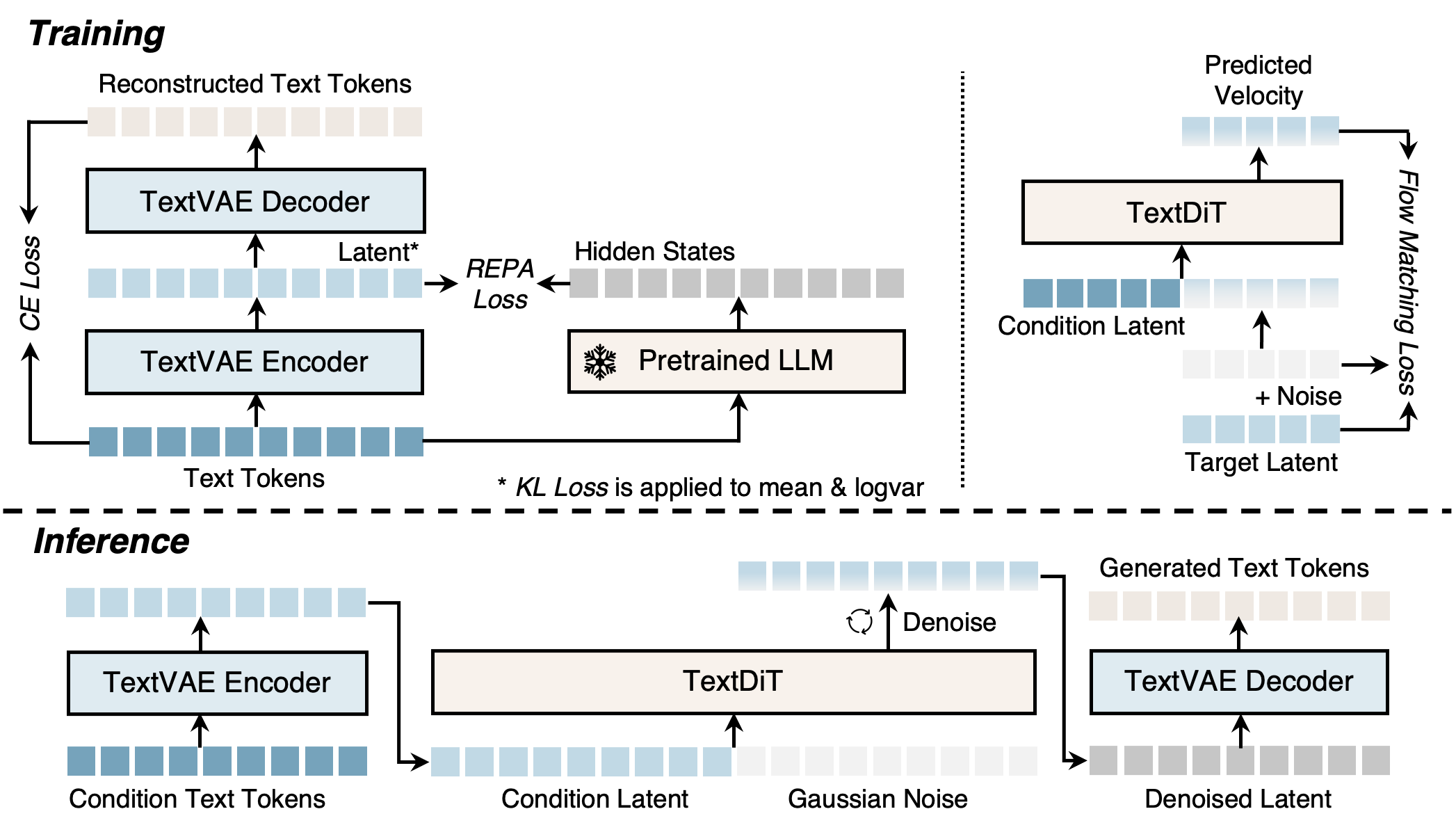
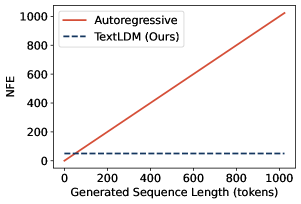
固定長の潜在グリッド上で動作することの実用的な帰結として、デコードのコストが系列長から切り離されます。すなわち、function evaluationの回数(NFE)はFMソルバーによって設定され、Nには依存しません。著者らは、ARの線形スケーリングとは対照的に、最大1024トークンまでNFEが長さに依存しないことを報告しています。
結果
OpenWebText2上で同一の設定のもとスクラッチから学習したTextLDMは、従来の拡散言語モデルを大幅に上回り、GPT-2と同等の性能を達成しています。連続潜在テキスト拡散における制約要因は再構成精度ではなくREPAであるという主要な主張は、アブレーションによって支持されています。再構成誤差は小さいがLM特徴量とのアラインメントがないVAEでは下流の生成性能が低いのに対し、Qwen3-1.7Bの特徴量へのアラインメントにより品質が回復しました。これは、CEによる再構成をより低くすることで十分とするという従来のtext-VAE研究における暗黙の仮定に反するものです。
限界と未解決の問題
- 本論文はOpenWebText2においてGPT-2クラスのベースラインと比較して学習を行っています。このレシピが現代のLLMの規模(10B+パラメータ、数兆トークンのコーパス)にスケールするかどうかは検証されておらず、また、Qwen3-1.7BによるREPAは事実上より強力なモデルからの蒸留であるため、同一計算量での比較が複雑になります。
- トークンと潜在変数の一対一対応は長さを保持しますが、画像の潜在拡散を魅力的にしていた圧縮性を放棄しています。潜在次元dとKL重みのトレードオフについては、深く探索されていません。
- 非自己回帰デコーダは、ノイズ除去が不完全な可能性のある潜在変数からトークンを並列に再構成しなければなりません。エラーモード(FMサンプリング下でのオフバイワンのズレや繰り返し)や、teacher-forcedなVAE再構成とエンドツーエンド生成のギャップについては、より詳細な分析が必要です。
- REPAのために事前学習済みLMに依存することは、鶏と卵の問いを提起します。連続テキスト潜在空間はスクラッチから学習できるのか、それとも根本的にAR教師モデルを必要とするのかという問題です。
なぜ重要か
GPT-2スケールで連続潜在拡散がAR言語モデリングに匹敵できるならば、視覚生成(DiT + VAE潜在空間におけるFM)とテキストを隔てるアーキテクチャの壁は交渉可能なものとなり、長さに依存しない推論コストで両モダリティを扱う単一のバックボーンへの道が開かれます。テキスト拡散を阻んできたのは拡散の目的関数ではなく潜在空間であるという自明ではない知見は、今後の研究努力をどこに向けるべきかを再定義するものです。
Source: https://arxiv.org/abs/2605.07748
誤差制御ダイナミクスを通じた再帰モデルにおける状態追跡の再考
問題設定
再帰アーキテクチャにおける状態追跡に関する文献は、表現力の問題に支配されてきました:あるアーキテクチャが G 上の目標とする記号的遷移規則を実現できるか、という問いです。本論文は、表現力は必要条件であるが十分ではないと主張します。同様に重要なのが誤差制御、すなわち記号的状態を区別する方向における隠れ状態のドリフトのダイナミクスです。あるモデルが各状態 g\in G を表現 c_g\in\mathbb{F}^d でエンコードするのに十分な表現力を持っていても、記号的部分空間 \mathcal{U}:=\operatorname{span}\{c_g - c_{g'}:g,g'\in G\} に沿った摂動が収縮しないために、長い水平線上での追跡に失敗する場合があります。これはまさに SSM および linear attention の変種が置かれている状況であり、群語問題に関するベンチマークの長さ汎化がなぜこれほど不安定であるかを説明しています。
手法と中心定理
中心的な対象は、状態保存列 s(すなわち G 上の記号的作用 T_s が恒等写像となる列)によって誘導されるリターンマップ F_s = F_{x_T}\circ\cdots\circ F_{x_1} です。厳密な実現には、すべての g に対して F_s(c_g)=c_g が要求されます。本論文は次の定理を証明します:
定理 1(アフィン中立性)。 F_s(h)=A_s h + b_s がアフィンであり、表現 \{c_g\} が非退化であり、すべての g に対して F_s(c_g)=c_g が成り立つならば、A_s|_{\mathcal{U}} = I である。
証明は簡潔です:差分 c_g - c_{g'} が \mathcal{U} を張り、F_s により固定されるため、A_s は張る集合上で恒等作用を持ちます。帰結は鮮明です: F_s(c_g + \delta) - F_s(c_g) = \delta \quad \text{for all } \delta\in\mathcal{U}.
すなわち、記号的遷移を厳密に実現するあらゆるアフィン再帰モデル——Mamba、Mamba-3、AUSSM、linear RNN、token-gated RNN(そのゲートが x_t のみに依存するため、更新が h_{t-1} についてアフィンとなる)——は、識別に重要なまさにその方向において収縮するアトラクタを持つことができません。アフィンモデルにおいては、\mathcal{U} 上での実現と修正は相互に排他的です。
状態依存的なマップはこれを回避します。c_g の周りの局所マップを p\mapsto F_s(c_g+p)-c_g と書いたとき、p=0 におけるヤコビアンのスペクトルノルムが一様に 1 未満であれば、\mathcal{U} に沿った摂動は収縮します。状態依存性は必要ではありますが十分ではなく、非線形性の選択がヤコビアン収縮を実際にもたらすものでなければなりません。
予測的帰結:有限水平線上の追跡
アフィンモデルは \mathcal{U} に沿った収縮ができないため、クラス内拡散 r_{\mathrm{err}}(t) は蓄積する一方、クラス間分離 r_{\mathrm{sep}}(t) は記号的作用によって固定されます。追跡が読み取り可能なのは、識別可能性比 q(t) = R(t)/M(t) がデコーダの読み取り可能閾値(最近傍セントロイド境界は q=1/2)を下回っている間のみです。q(t) がこの閾値を超える水平線が、テスト精度が維持される最大長を予測します。
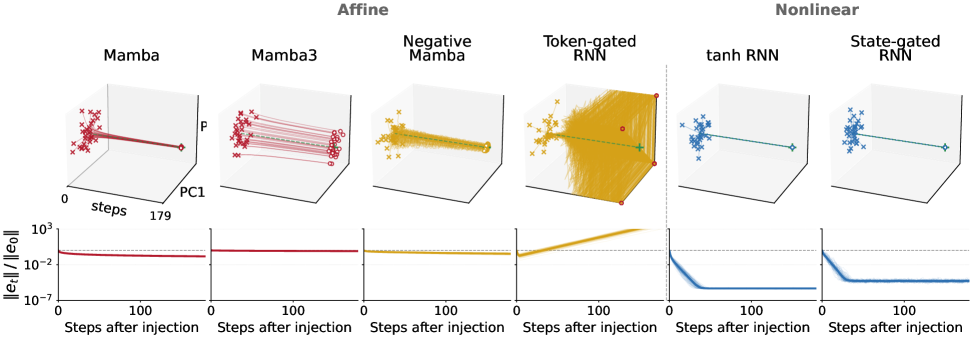
図 1 は S_3 上の摂動実験を示しています:ノイズ注入後、アフィンモデルはグローバルに減衰するか(Mamba、Mamba-3、Negative Mamba——ただし非記号的方向も含めて一様であり、\mathcal{U} 上の修正とは異なります)、グローバルに拡大します(Token-gated RNN)。状態依存の tanh RNN と State-gated RNN のみが、重要な場所に集中した誤差収縮を示しています。
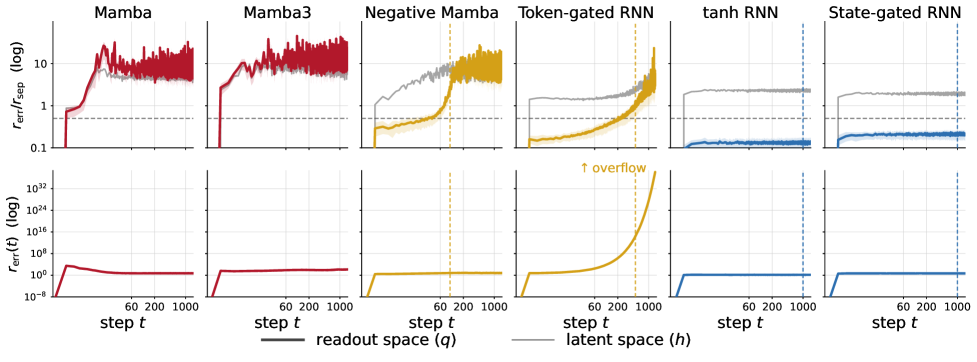
図 2 は予測を定量的に示しています:表 2 における各アフィンモデルの経験的最大通過長 \mathrm{mp} は、q(t) が 1/2 境界を超える点と一致します。状態依存モデルは q(t) を無限に有界に保ちます。
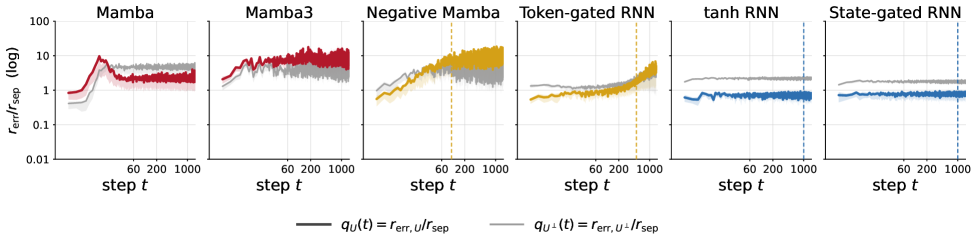
図 3 は拡散を q_{\mathcal{U}}(t) と q_{\mathcal{U}^\perp}(t) に分解し、アフィンモデルの失敗がまさに定理 1 が予測するとおり \mathcal{U} に沿って生じていることを確認しています。
定量的結果
学習は長さ \le 60 で行われ、評価は長さ 1000 まで拡張されます。60 と報告されているセルはカリキュラム長でのみ生き残るモデルを示し、✗ は \mathrm{mp}=0 を意味します。
- C_2(1層)の場合:vanilla Mamba と Linear RNN は失敗(✗);Mamba-3 は 200 に到達;AUSSM と Negative Mamba は 1000 に到達;Token-gated RNN は 1000 に到達。
- C_6(1層)の場合:すべてのアフィンモデルは \le 300 で上限に達し(Token-gated RNN)、Mamba と Linear RNN は ✗。
- S_3(非可換、より困難)の場合:Negative Mamba(100)と Token-gated RNN(500)を除き、すべてのアフィンモデルが L1 で外挿に失敗。2 層スタックは僅かに改善し(Token-gated RNN は 1000 に到達)。
- 状態依存の tanh RNN と State-gated RNN はすべてのタスク、すべての深さで 1000 に到達。
Token-gated RNN は定理の最も明確なストレステストです:豊富なゲーティングを持ちますが、ゲートが x_t のみに依存するため更新は依然として h_{t-1} についてアフィンであり、より簡単なタスクで 500〜1000 に到達するにもかかわらず有限水平線失敗モードを継承しています。
制限と未解決問題
定理は厳密なアフィン実現に関するものです;実際にはモデルは近似的に学習されており、Mamba のような「グローバル収縮」アフィンモデルは \{c_g\} を厳密に固定せず \mathcal{U}^\perp も減衰させるコストを払いながら \mathcal{U} 上の誤差を減衰させます。このフレームワークは水平線を予測しますが、どの程度の状態依存性が必要か、また深いスタックでどの非線形性がヤコビアン収縮をもたらすかは規定しません。群語問題は制御されたプローブです;q(t) がより構造化されていないタスク(例えば暗黙的に状態追跡を必要とする言語モデリングのような設定)での失敗を予測するかは未解決です。最後に、分析は層ごとのものです;深さはアフィンブロックからでも非アフィンな合成を可能にし、L1\toL2 の僅かな改善はこれを示唆していますが定量化はされていません。
この研究の重要性
表現力の議論は状態追跡に対して SSM と linear attention が適切であると擁護するために使われてきましたが、本論文はあらゆるアフィン再帰が構造的不可能性に直面することを示しています:記号的表現を固定することと、それらの間の摂動を収縮させることを同時に行うことはできません。識別可能性比は、追跡がいつ崩壊するかについてモデル非依存の予測的水平線を与え、「長さ汎化」をアーキテクチャの容量の問題としてではなく誤差制御の問題として再定式化します。
Source: https://arxiv.org/abs/2605.07755
MACE-Dance: 音楽駆動ダンス動画生成のためのモーション・アピアランス縦続専門家モデル
問題設定
音楽駆動ダンス動画生成には、運動学的に妥当で音楽と同期した人体モーションと、参照画像のアイデンティティを保持する時空間的に一貫したレンダリングを同時に生成することが求められます。従来のアプローチはパイプラインの断片的な部分しか扱っていません:音楽から3Dモーションへの手法(EDGE、Lodge)はアピアランスを無視しており、ポーズ駆動型アニメーター(Hallo2、Echomimic-V3、WAN-S2V など)は外部から供給されたドライビング信号を必要とし、音楽を直接条件として使用できません。音楽から動画への直接学習は、音声がピクセルレベルのアピアランスに関して弱いシグナルしか持たないため、偽りのクロスモーダル相関に悩まされます。
手法
MACE-Dance は、SMPLパラメータにおける明示的な3Dモーションボトルネック X \in \mathbb{R}^{T \times C_x} を介して、p(D \mid M, I) を2つの専門家の縦続(カスケード)に分解します:
p(D \mid M, I) = \int p_{\text{AE}}(D \mid X, I)\, p_{\text{ME}}(X \mid M)\, dX.
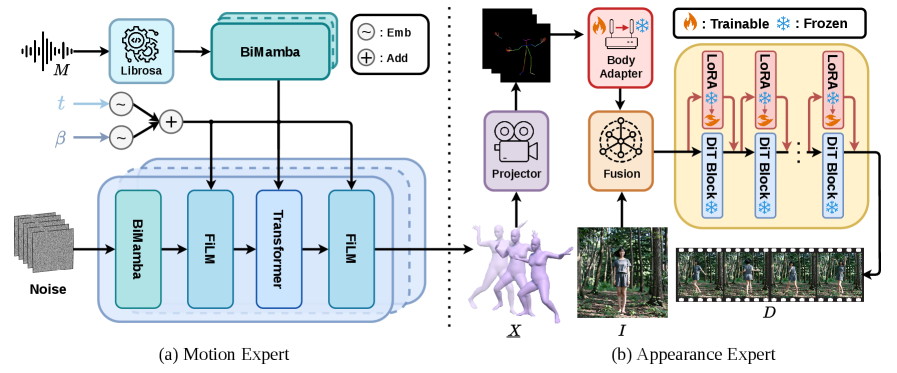
著者らが3Dを2Dキーポイントよりも選ぶ理由として、(i) グローバルな並進・向きが保持される、(ii) 監督信号がカメラや体型比率から切り離される、(iii) 自己遮蔽が暗黙的に処理される、という点を挙げています。手先は(SMPL-Xではなく)SMPLのみを使用するために除外されており、現在のデータスケールでは体幹のみのモーションで十分とされています。
Motion Expert(ME)。 BiMamba–Transformer ハイブリッドバックボーンを持つ diffusion model:2つの BiMamba 層と Genre-Gate が音楽の条件付けを処理し、続く8つの BiMamba-Transformer ブロックがモーションベクトルを生成します。Mamba ユニットは状態サイズ16、カーネル4、拡張率2、潜在次元512を使用し、Transformer ブロックは4ヘッド、FFN 1024、dropout 0.1、GELUを使用します。学習では再構成、3D関節位置、速度、および足接触の loss を重み \lambda_{rec}=0.636、\lambda_{joint}=0.636、\lambda_{vel}=2.964、\lambda_{foot}=10.942 で組み合わせます。FineDance データセットで4000エポック学習し、バッチサイズ128、Adam lr 4\times 10^{-4}、weight decay 0.02、EMA decay 0.9999、8台のH20 GPUを使用します。学習シーケンスは240フレーム(8秒)で、推論時は1024フレーム(34.13秒)まで拡張可能です。
重要な点として、MEはGuidance-Free Training(GFT)を採用しており、classifier-free guidance の代わりに \beta 条件付きモデルを用いて条件付き挙動と非条件付き挙動を補間します。これにより、推論時に単一のフォワードパスで多様性と忠実度のトレードオフ曲線上の所望の点を達成できます。表7のアブレーションがそのトレードオフを検証しています:\beta=1.00 は最高の多様性(\mathrm{DIV}_k=13.29、\mathrm{DIV}_g=9.68)を示しますが忠実度が最低(\mathrm{FID}_k=29.35、\mathrm{FID}_g=31.91)であり、\beta=0.50 では逆転し(\mathrm{FID}_k=15.11、\mathrm{FID}_g=24.15、\mathrm{DIV}_k=8.64、GT の 9.94 を下回る)、\beta=0.00 は数値的に不安定(NaN)です。デフォルトの \beta=0.75 では \mathrm{FID}_k=17.83、\mathrm{FID}_g=25.09、\mathrm{DIV}_k=10.30、\mathrm{DIV}_g=8.09、\mathrm{BAS}=0.229 となり、多様性は ground truth を上回り、\beta=1.00 と比較して大幅に優れた忠実度を実現しています。
モーション編集。 MEが構造化された3Dモーションを扱うため、マスク付き DDIM denoising、
\tilde{z}_{t-1} = m \odot q(x^{\text{known}}, t-1) + (1-m) \odot \hat{z}_{t-1},
により、再学習なしに時間的なイン・ビトウィーニング、関節単位のインペインティング(例:上半身を固定して下半身を再生成)、および軌跡誘導生成(ルート並進の制約)をサポートします。
Appearance Expert(AE)。 「分離された運動学的」設計(要旨は提供されたテキストで途中で切れています)を持つ、モーションと参照画像を条件とした動画合成器です。SMPLシーケンス X と参照画像 I を入力として受け取り、モーション中心のサブセットではなくMA-Data全体のコーパスで学習されます。
データ
著者らはMA-Dataをキュレーションしています:20以上のダンスジャンルにわたる合計116時間の70kクリップ(各5〜10秒)です。2つの補完的なサブセットとして、(i) キャラクターに再ターゲットされフロントビューでレンダリングされた FineDance モーションの20kクリップ(約28時間、モーション中心、MEの学習に使用)と、(ii) TransNet V2 によるショット検出、静止クリップに対する optical-flow 大きさフィルタリング、および ViTPose による単一パフォーマー強制によりクリーニングされたインターネット上の野生の50kクリップ(約88時間、アピアランス中心)があります。TikTokからの200本の5秒クリップを別途テストセットとして保留しています。
結果
30本の8秒音楽セグメントを対象に、ダンス訓練を受けた40名の参加者による嗜好ベースのユーザースタディにおいて、MACE-Dance はHallo2、EDGE、Lodge、WAN-S2V、Echomimic-V3に対して、6つすべての評価軸(モーション:DS、DQ、DC、アピアランス:PQ、TC、IC)で優れた評価を得ました。定性的には、ベースラインには特徴的な失敗パターンが見られます:Hallo2は顔をぼかして背景にアーティファクトを生じさせ、EDGEは急激なモーションの不連続を示し、Lodgeは物理的に不自然なポーズを生成し、WAN-S2VとEchomimic-V3は反復的で振幅の小さいモーションを生成します。MACE-Dance は実在人物とアニメの両方の参照画像、および東洋民族舞踊とポッピング音楽の両方にわたって、一貫したアピアランスと表現力豊かなモーションを維持しています。

限界と未解決の問題
- MEは体幹のみ(SMPL、手・顔なし)であり、ラテンやK-Popなどのジャンルにとって重要な指先や顔の微細な動きはモデル化されていません。
- MEとAEは互いに異なるデータサブセットで学習されているため、カスケードを通じた誤り伝播が明示的に最小化されていません。AEはMEのSMPL軌跡に含まれるアーティファクトをそのまま受け継いでしまいます。
- ユーザースタディでは絶対的なスコアリングではなく嗜好選択を使用しているため、各ベースラインとの評価軸ごとの効果量は提供されたテキストでは定量化されていません。
- 動画レベルの定量的指標(FVD、アイデンティティ類似度、時間的一貫性)は抜粋では報告されておらず、アピアランス評価は主にユーザー嗜好に依存しています。
- AEにおけるアイデンティティ保持は明らかなディープフェイク悪用リスクをもたらします。著者らはこの問題を指摘していますが、一般的な安全策(透かし、来歴)のみを提案しています。
- 長期的なコヒーレンス:MEは1024フレームのシーケンスを生成しますが、学習は240フレームであり、外挿領域の定量的な検証がなされていません。
重要性
このカスケード設計は、音楽条件付きモーションセマンティクスとアイデンティティ条件付きレンダリングの間に明確な分離を強制し、明示的な3Dモーションをインターフェースとして使用します。これにより、アピアランス段階でのペア(音楽、動画、アイデンティティ)教師データが不要になるとともに、リグ、アバター、ヒューマノイド制御への転用可能な再利用可能なモーションアセットが得られます。モーション diffusion における CFG を GFT で置き換えることは、\beta でインデックス付けされた多様性と忠実度のトレードオフの族を、テキスト以外の生成タスクにおいて単一モデルで学習できることの具体的な実証です。
Source: https://arxiv.org/abs/2512.18181
Hacker News Signals
LLMにドキュメント処理を委任すると内容が改ざんされる
Source: https://arxiv.org/abs/2604.15597
本論文は、LLMをエージェントとして文書の編集・要約・変換などに使用した際に生じる系統的な障害モードを記録したものです。具体的には、委任されたタスクの範囲を超えて、モデルが無断で意味的な変更——言い換え、省略、内容の微妙な改変——を加えるという問題です。著者らはこれを「ドキュメント腐敗(document corruption)」と呼び、幻覚(hallucination)とは区別される概念として位置づけています。モデルは世界に関する事実を捏造しているのではなく、エージェントとしてのタスクを忠実に遂行しながら、原文をひそかに劣化させているのです。
本研究では、複数のフロンティアモデル(GPT-4o、Claude 3.x、Gemini 1.5)を対象に、コピー編集・フォーマット変換・翻訳・内容保持指示付き要約といった文書操作タスクのベンチマーク上で評価を行い、語彙レベル・意味レベル・事実レベルでの原文との乖離を計測しています。中心的な知見は、モデルが系統的に過剰編集を行うというものです。内容を保持するよう明示的に指示された場合でも、モデルは言い換え・圧縮・再構成を行います。この乖離はランダムではなく、モデルの能力と相関しており——能力の高いモデルほど腐敗をより流暢に行うため、変更の検出が困難になります。
提案されているメカニズムとして、instruction-tuningされたモデルは「役に立つ」ように訓練されており、それは実際には洗練されたアウトプットを生成することを意味するため、この訓練目標が厳密な忠実性制約と衝突するというものがあります。RLHF の reward signal は滑らかな言い換えを罰しないため、モデルは書き直しをデフォルトで許容されるものとして学習してしまいます。
本論文では、トークンレベルの編集距離と意味的類似度(embedding のコサイン距離を使用)、およびNLIモデルによる事実整合性スコアを組み合わせた忠実性考慮型の評価指標を提案しています。この指標のもとで、テストされた全モデルは、同等の指示を与えられた人間の編集者を大幅に下回るスコアを記録しました。
実用的な観点からは、大規模な文書処理を行うエージェントパイプライン——逐語的な忠実性が重要となる法律・医療・アーカイブの文脈——において深刻な懸念事項です。本論文は訓練上の改善策を提示しておらず、全般的な能力を損なうことなく真の忠実性制約をどのように植え付けるかという問いは未解決のまま残されています。プロンプトによる緩和策(差分のみを出力する指示、構造化された出力フォーマット)は腐敗を軽減しますが、完全には排除できません。
ClaudeがユーザースペースIPスタックとして動作する場合、Pingへの応答速度はどのくらいか?
Source: https://dunkels.com/adam/claude-user-space-ip-stack-ping/
uIPおよびlwIPの作者であるAdam Dunkelsが、ClaudeにユーザースペースのユーザースペースのユーザースペースのユーザースペースのユーザースペースのユーザースペースのユーザースペースのユーザースペースのユーザースペースのIPスタックをPythonで実装させ、そのスタックに対してICMPエコーのラウンドトリップレイテンシをベンチマーク計測しました。技術的な内容は、一見した印象よりもはるかに興味深いものです。
Claudeは、Ethernetフレームのパース、IPヘッダの構築(チェックサム計算を含む)、そしてICMPエコー応答の生成を処理する、rawソケットベースの機能的なPython実装を生成しました。これはuIPがC言語の数百行で実現しているコア機能を、プロンプトからPythonで再現したものです。DunkelsはICMPを別のホストから実際に送信し、応答を受信することで正確性を検証しました。
レイテンシの数値は予想通り大きく、ラウンドトリップタイムは数百ミリ秒から数秒程度であり、ネットワーク的な要因ではなくLLMのトークンごとの推論時間に完全に支配されています。DPDKのような実際のユーザースペーススタック、あるいは8 MHzの組み込みMCU上で動作するlwIPでさえ、1ミリ秒以内にpingへ応答します。この比較が真剣なベンチマークでないことは明らかです。
技術的に注目すべき点はコードの品質です。生成されたスタックは、IPチェックサム計算(ヘッダワードに対する1の補数和)を正しく処理し、可変長のIPオプションをパースし、送信元・送信先を入れ替えてICMPチェックサムを再計算することで有効なICMPタイプ0の応答を構築しています。これらはビットレベルの詳細であり、単純なコード生成がしばしば誤りを犯しやすい部分です。Dunkelsはひとつのサブレなバグを指摘しています——TTLフィールドがデクリメントされていないという点ですが、これはエンドホストとしては正しい動作であり、ルータであれば誤りとなります——これはモデルがセマンティックなコンテキストを理解していたことを示唆しています。
より広範な技術的論点は、プロトコル実装ツールとしてのLLMに関するものです。低リスクやプロトタイピングの文脈では、モデルは高レベルの記述から構造的に正確なネットワークコードを生成することができます。失敗のモードは構造的なものではなく、微妙なもの(ヘッダオフセットのOff-by-one、エンディアンネス)であり、これはRFCおよびネットワークコードを豊富に学習したモデルから期待される挙動と一致しています。
Killswitch: 関数単位のショートサーキット緩和プリミティブ
Source: https://lwn.net/ml/all/20260507070547.2268452-1-sashal@kernel.org/
Sasha Levinによるこのパッチシリーズは、killswitch メカニズムを提案しています。これは関数単位のバイナリフラグであり、セットされると当該関数がそのボディを実行せず即座にリターン(ショートサーキット)するものです。その目的は、カーネルイメージから安全に削除できないが、アクティブなエクスプロイトへの対応やデバッグ時に無効化する必要がある既知の脆弱な関数に対する、軽量かつランタイムで制御可能な緩和プリミティブを提供することです。
実装は、static callやジャンプラベルと精神的には類似した形で、ランタイムに関数のプロローグを条件分岐命令でパッチして早期リターンへと誘導することで動作します。ただし追加のセマンティクスとして、関数はエラーコードではなく安全なデフォルト値(ゼロ/NULL)を返します。これは、オーバーヘッドが大きい ftrace や、追加に再コンパイルが必要な static_key といった既存のメカニズムとは異なります。killswitchはsysfsインターフェースまたはカーネルコマンドラインからトグルできます。
機械的な実装にはテキストパッチングを使用します。起動時に関数エントリにNOPが発行され、killswitchが有効化されると、そのNOPがゼロ化されたリターン値で ret を実行するトランポリンへのジャンプに置き換えられます。x86では5バイトのニアジャンプが使用されます。このパッチは、ジャンプラベルで使用されている既存のBPベースのパッチングメカニズムである text_poke_bp に依存しており、SMPシステムでの正確性を保証します。
未解決の問題として、呼び出し元に対するセマンティクス上の契約が挙げられます。関数がエラーコードではなく0/NULLを返すと、呼び出し元が成功したかのように処理を続行し、新たな障害モードを生む可能性があります。メーリングリスト上のRFCの議論でもまさにこの点が指摘されています。場合によっては、暗黙のゼロよりもパニックや明示的なエラーリターンの方が安全である可能性があります。また、lockdepやRCUとの相互作用という問題もあります。ロックを取得したりRCUリードを実行したりする関数は、カーネルの状態を不整合にすることなく単純にショートサーキットすることができません。
ClaudeによるFirefoxのセキュリティ強化:Mythos Previewの活用
Source: https://hacks.mozilla.org/2026/05/behind-the-scenes-hardening-firefox/
MozillaはAnthropicのClaude Mythos Preview(コーディングに特化したモデル変種)を活用し、FirefoxのC++コードベースに対するセキュリティ強化をスケールで実施した経緯を紹介しています。技術的な作業は2つのカテゴリに分類されます。一つは安全でないメモリパターンの自動検出と修正、もう一つはfuzzingハーネスの生成です。
メモリ安全性については、C++ソースコードの各セクションと一連の強化ルール(生のポインタ+長さのペアよりmozilla::Spanを優先する、手動のnew/deleteをUniquePtrで置き換える、サイズ計算における未チェックの整数演算にフラグを立てる)をClaudeに与えるワークフローを採用しています。Claudeがdiffを提案し、エンジニアがレビューしてランドするという流れです。Mozillaによると、レイアウトエンジンやIPC層を含むコアコンポーネント全体で数万行を処理したと報告されています。clang-tidyのような静的解析ツールとの差別化ポイントは、呼び出しコンテキストの理解を要するリファクタリングをClaudeが処理できる点です。たとえば、末端の関数にフラグを立てるだけでなく、コールスタックの3層を通じてSpanを伝播させるといった対応が可能です。
fuzzing については、関数シグネチャとdocコメントを与えることでLLVMFuzzerTestOneInputハーネスを生成します。これは主にテンプレートを埋める作業ですが、興味深い点は、明示的な仕様なしにコードコンテキストからClaudeが入力制約(例:バッファはnull終端でなければならない、長さパラメータはゼロ以外でなければならない)を推論することです。その結果、単純なランダムバイトfuzzingよりも深いコードパスに到達するハーネスが生成されます。
この記事は失敗モードについても率直に述べています。Claudeが生成するdiffは、構文的には正しくても意味的に誤っている(不正確なライフタイムの仮定、リファクタリング後のnullチェック漏れ)ことがあります。人間によるレビュー層は必須とされており、完全自律的なセキュリティ強化の実現は主張されていません。
論じられていない点としては、LLMが提案するdiffの偽陽性率、fuzzingハーネスが新たなバグを発見したかどうか、そしてMythos Previewが標準的なClaude 3.xとアーキテクチャ的にどう異なるかが挙げられます。定量的なセキュリティ上の成果が示されていないことは、顕著な情報の欠落です。
Gemini API File Searchがマルチモーダルに対応
GoogleはGemini APIのFile Search(アップロードされたファイルに対するRAG)機能を拡張し、マルチモーダルなクエリをサポートするようになりました。検索ステージにおいて、テキストチャンクだけでなく、画像コンテンツ・表・グラフ・混合モダリティのドキュメントとのマッチングが可能になっています。
技術的なメカニズムとしては、Geminiのネイティブなマルチモーダルembeddingを活用しており、画像・テキスト・構造化データを共通のベクトル空間にマッピングします。インデックス作成時には、アップロードされたファイルがチャンク分割され、各チャンクがマルチモーダルエンコーダによってembeddingされます。クエリ時には、テキストまたは画像のクエリが同じ空間にembeddingされ、近似最近傍探索によって関連チャンクが取得されます。取得されたチャンク(画像タイルを含む)は、回答生成のためにGeminiのコンテキストウィンドウに直接渡されます。
重要な制約として、検索は依然としてembeddingベースの類似度検索であり、構造化検索ではありません。そのため、「Q3の収益を示す棒グラフを見つけて」といったクエリは、マルチモーダルembeddingがそのセマンティックな内容をどれだけ正確に捉えられるかに依存します。テキストラベルが少ないグラフや図については、テキストが豊富なドキュメントと比較してembeddingの品質が低下します。このシステムはembeddingの前にグラフから構造化データを抽出するわけではなく、レンダリングされた画像パッチに対して処理を行います。
APIの観点では、すでにFile Searchを使用している開発者にとってインターフェースは変わりません。アップロードされたファイルは自動的に新しいマルチモーダルエンコーダでインデックス化され、クエリはテキストと画像チャンクが混在した形で返されます。多数の画像を含む長いドキュメントに対しては、取得コンテンツのコンテキストウィンドウ予算が依然として制約となります。
実用上の制限事項として、動画のキーフレーム検索はまだサポートされておらず、ANNインデックスは設定(HNSWパラメータ、量子化)を公開しておらず、またハイブリッドのsparse-dense検索オプションも存在しません。このハイブリッド検索は、キーワード固有のクエリに対する精度向上に一般的に効果的です。異種ドキュメントコーパスを対象とした本番RAGシステムにおいて、dense検索と並行したBM25スタイルの単語マッチングが欠如している点は、ハイブリッド検索を有効にしたVespaやWeaviateのような特化型パイプラインと比較した場合の最も重要なギャップです。
注目の新規リポジトリ
raiyanyahya/how-to-train-your-gpt
コードの全行にインラインコメントが付いており、各行の目的を説明したゼロから始めるGPT実装です。このリポジトリは、トークン化(BPE)、embedding レイヤー、因果マスクを用いたマルチヘッド self-attention、位置エンコーディング、フィードフォワードサブレイヤー、Layer Normalizationの配置、そしてcross-entropy lossを用いた基本的な学習ループという、完全なトレーニングスタック全体を解説しています。教育的な意図は明確であり、導出を既知のものとは仮定しないため、コメントでは残差ストリームがなぜ存在するのか、attention における \frac{1}{\sqrt{d_k}} というスケーリング係数が何を実現するのか、そしてembedding行列とunembedding行列間のweight tyingがどのように機能するかを説明しています。アーキテクチャは元のGPT-1の構造ではなく、モダンなGPT-2クラスのモデルを対象としており、pre-LayerNormと学習済み位置embeddingを採用しています。論文が読み飛ばしがちな実装の詳細、すなわちgradient checkpointing、推論時のkey-valueキャッシュの構築、またはバッチ処理されたattentionカーネルを流れる正確なテンソルの形状について直感を養いたい読者にとって、有用なリファレンスです。分散学習、FSDP、flash attentionの各バリアントはカバーされていないため、単独のトレーニングレシピとしてではなく、より本番環境向けのコードベースと併せて読むことが最適です。
Source: https://github.com/raiyanyahya/how-to-train-your-gpt
amitshekhariitbhu/llm-internals
LLMの内部構造を複数の抽象レイヤーにわたって体系的に扱うカリキュラムです。このリポジトリは、トークン化アルゴリズム(BPE、WordPiece、SentencePiece)から始まり、transformer blockの詳細——QKVプロジェクション、multi-head attention、grouped-query attention(GQA)、rotary positional embeddings(RoPE)、RMSNorm対LayerNormのトレードオフ——を経て、KV caching、speculative decoding、量子化戦略(INT8、GPTQ、AWQ)といった推論時のメカニズムへと進んでいきます。各トピックは、散文だけでなく数式と注釈付きコードスニペットを用いて解説されています。推論最適化のセクションは特に具体的で、prefillフェーズとdecodeフェーズを区別し、自己回帰生成においてメモリ帯域幅がボトルネックとなる理由を説明し、continuous batchingがGPU利用率をどのように改善するかを示しています。このリポジトリはモデルをスクラッチから学習するものではなく、最小限の実行可能なサンプルを補足とした読書・参照用ガイドです。ポストトレーニング(RLHF、DPO)についても扱われていますが、アーキテクチャのセクションと比べると内容は薄めです。transformer論文を読める水準にあるものの、論文が省略しているエンジニアリングの文脈を求めている方に有用です。
Source: https://github.com/amitshekhariitbhu/llm-internals
future-agi/future-agi
Apache 2.0ライセンスのセルフホスト可能なオブザーバビリティ・評価プラットフォームで、LLMアプリケーションおよびマルチエージェントパイプラインを対象としています。主要コンポーネントは以下の通りです:OpenTelemetry互換のスパンを通じてLLMの呼び出しやエージェントのツール呼び出しを計装するトレーシングレイヤー;トレースされた出力に対してモデルベースおよび決定論的なスコアラーを実行する評価エンジン;制御された条件下でエージェントの軌跡を再生するシミュレーションハーネス;評価セットのキュレーションとバージョン管理を行うデータセットストア;ルーティング・認証情報管理・レート制限を一元化するLLMゲートウェイ;そして推論時に出力制約を適用するガードレールモジュールです。アーキテクチャはデータプレーン(トレーシング、ゲートウェイ)と評価プレーンを分離しており、計装のオーバーヘッドが評価パイプラインをブロックしない設計となっています。セルフホスティングはPostgresとPythonバックエンドを用いたDocker Composeによってサポートされています。このプラットフォームのスコープはLangSmithやWeights and Biases Weaveと広く比較可能ですが、コードベースを完全にオープンにしている点が異なります。反事実的なエージェント実行をサポートするシミュレーションコンポーネントは、既存のオープンソースオブザーバビリティツールと比較して最も差別化された機能です。
Source: https://github.com/future-agi/future-agi
oritera/Cairn
Cairnは、自律的なペネトレーションテストを汎用の状態空間探索問題として定式化します。このエージェントは明示的な状態グラフを維持しており、ノードはシステムの構成(オープンポート、発見された認証情報、権限レベル)を表し、エッジはアクション(エクスプロイトの試み、ラテラルムーブメントのステップ)を表します。このグラフ上での探索は、目標への近さを推定するヒューリスティック関数によって誘導され、深さ優先探索と最良優先探索の両方のトラバーサルポリシーをサポートしています。LLMコンポーネントは、現在の状態記述に基づいて候補となるアクションを提案するプランナーとして機能し、シンボリックな検証器が実行前に前提条件をチェックします。このハイブリッド設計により、LLMのみのエージェントが持つ純粋なprompt-chainingの脆弱性を回避しつつ、ルールベースのシステムでは列挙できない新規の攻撃対象に対する柔軟性を維持しています。検証は、実際のターゲットではなく、標準的なCTF形式の環境とシミュレートされたネットワーク上で行われます。状態空間による定式化がこの研究の実質的な貢献であり、中間状態を明示的に追跡しなければならない長期的な部分観測タスクを扱うための原則的な方法を提供します。同じエンジンがペネトレーションテスト以外の領域にも適用できるという汎用性の主張は述べられていますが、リポジトリ内では経験的にはまだ実証されていません。
Source: https://github.com/oritera/Cairn
kyegomez/OpenMythos
Anthropicの内部フレームワーク「Mythos」——Claudeの公開モデル仕様に記述されたアイデンティティ、キャラクター、および価値アラインメントの足場——をファーストプリンシプルから実装した、推測的なリバースエンジニアリングです。このリポジトリは、そのドキュメントに登場する概念(キャラクターの一貫性、corrigibilityのグラデーション、principal hierarchy、Constitutional AIスタイルの自己批判)を、具体的なトレーニングおよび推論コードとして運用可能な形に落とし込もうとしています。主要コンポーネントとして、helpfulness・harmlessness・honestyを設定可能な重み付きで同時スコアリングするmulti-objective reward model、モデルが自身の下書き応答を明示された原則に照らして問い直すdebate形式の自己批判ループ、そしてoperatorレベルとuserレベルの命令を差分的な信頼度で区別するprincipal hierarchy抽象化が含まれています。実装には標準的なtransformer fine-tuningおよびRLHFインフラが使用されています。スター数(12k+)は、実証的な検証よりも解釈可能なアラインメントの足場に対するコミュニティの関心を反映しており、このリポジトリは明示的に理論的なものであり、Claudeや同等モデルに対するベンチマーク結果は提供されていません。本リポジトリの主な価値は、Claudeのモデル仕様を実行可能な疑似コードに翻訳した構造化された読み解きとしてのものであり、プロダクション向けのアラインメントシステムとしてのものではありません。